
|
| 8. CFS-Display/Editor |
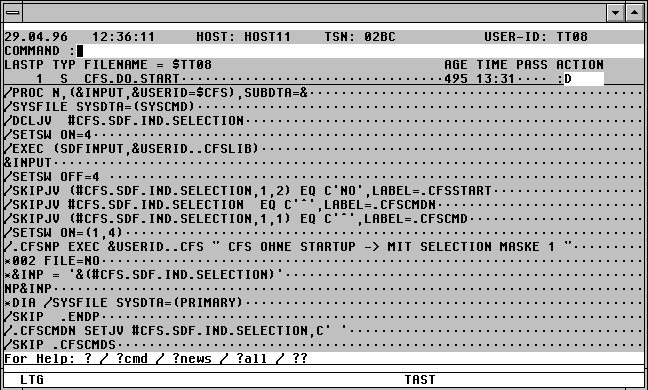
|
 Durch Klicken mit der Maus erhalten Sie eine Beschreibung zum gewünschten Feld. |
| Nicht abdruckbare Zeichen werden im CFS-Display durch das "Schmierzeichen" X'07' dargestellt. Die Entscheidung, welche Zeichen als "abdruckbar" gelten, wird getroffen aufgrund des CCS der Datei sowie des Terminaltyps, auf dem CFS läuft. |
| Läuft CFS auf einem nicht 8-bit fähigen Terminal, werden grundsätzlich alle nicht ein einem 7-bit Code definierten Zeichen als Schmierzeichen dargestellt. |
| Im Display-Modus werden bei Dateien mit einem 8-bit CCS (z.B. EDF041) auf einer Terminalemulation vom Typ 9763-8 (8-bit) alle in diesem CCS definierten Zeichen korrekt angezeigt. |
| Gemäß der Standard Umsetztabelle werden Kleinbuchstaben auch dann am Bildschirm dargestellt, wenn der LOW-Modus nicht eingeschaltet ist (siehe hierzu die Kommandos CAP/LOW). |
| Unterstützung von Unicode Objekten in CFS | |
| Ab der BS2000-Version 7.0 werden Unicode-Objekte unterstützt. | |
| Unter Unicode-Objekten verstehen wir Dateien/PLAM-Bibliothekselemente, deren Datensätze in einem der folgenden CCS (Coded Character Sets) codiert sind: UTF16 (= UNICODE), UTF8, UTFE. Die Codes der alphanumerischen Zeichen (A - Z, a -z, 0 - 9) sind in UTF16 und UTF8 grundsätzlich verschieden vom EBCDIC-Code. Unter UTFE besitzen zumindest die alphanumerischen Zeichen die gleichen Codes wie in EBCDIC. | |
| Im Display-/Modify-Modus von CFS werden die Inhalte von Unicode-Objekten in lesbarer Form dargestellt. Voraussetzung hierfür ist BS2000 >= 7.0 (XHCS Version >= 2.0), sowie der zur Codierung passende CCS-Eintrag im Systemkatalog bzw. im Inhaltsverzeichnis der PLAM-Bibliothek. Siehe hierzu auch die CFS User Option CCS. | |
| DA UNI,EDF0xxx |
| Erkennt CFS eine Unicode-Datei am zugehörigen CCS-Eintrag, so wird intern das Kommando DA UNI,EDF04F ausgeführt. Der Benutzer kann jedoch selbst ein anderes Kommando DA UNI,EDF04xx eingeben, falls z.B. das Euro-Zeichen nicht an der erwarteten hexadezimalen EBCDIC-Position steht. | |
| Das Kommando DA UNI,EDF04xx bewirkt folgendes: | |
| a) | Läuft CFS unter einer 8-bit Emulation, so werden alle Unicode-Zeichen, die im 8-bit Character Set EDF04xx darstellbar sind, zur Bildschirmanzeige in diesen Code umgesetzt. | |
| b) | Läuft CFS unter einer 7-bit Emulation, so werden alle Unicode-Zeichen, die im 7-bit Character Set EDF03IRV darstellbar sind, zur Bildschirmanzeige in diesen Code umgesetzt. | |
| Alle Unicode-Zeichen, die im gewählten Code nicht definiert sind, werden als Schmierzeichen (X'08') dargestellt. | |
| Im Hexadezimal-Modus von CFS (Display-Kommando H) werden die Daten der Unicode-Datei in der EDFxxx-Codierung angezeigt. Damit können auch im Hexa-Modus keine Unicode-Zeichen eingegeben werden, die außerhalb der EBCDIC Codevarianten liegen. | |
| Um ein Unicode-Objekt im native-Modus, d.h. in der originalen, nicht umgesetzten Codierung anzuschauen, ist das CFS-Kommando NDA einzugeben. Bei UTF16-Dateien wird in diesem Fall jedes Zeichen als 2-Byte Folge dargestellt. Die gewohnten alphanumerischen Zeichen sind dann für den Benutzer nicht mehr erkennbar. Im Hexadezimalmodus können jedoch, falls bekannt, die Codierungen von fremdsprachlichen Zeichen (z.B. Kyrillisch) modifiziert werden. | |
| DA CODE,UTFxxTOEBC |
| Mit diesem Kommando können die alphanumerischen Zeichen von Unicode codierten Dateien auch ohne korrekten CCS-Eintrag im Katalog, bzw. in älteren BS2000-Versionen < 7.0 in einer lesbaren Form am Bildschirm angezeigt werden. Eine Änderung der Dateninhalte ist hierbei jedoch nicht möglich. | |
| Falls eine Datei keinen, bzw. einen falschen CCS-Eintrag im Katalog besitzt, kann man mit | |
| DA CODE,UTF16TOEBCD | |
| DA CODE UTF8TOEBCD | |
| den tatsächlich für die Codierung der Daten verwendeten CCS testen und der Datei evtl. mit /MOD-FILE-ATTR datei,C-C-S=code zugewiesen. | |
| Es ist zu beachten, daß bei der UTF16 Codierung alphanumerische Zeichen als 2-Byte mit führendem Leerzeichen dargestellt werden. | |
| Inhalt von Dateien/Bibliothekselementen umcodieren | |
| ONXCONV ['str1'= 'str2', ] CCS=ccsneu [, FCCS=ccsalt] |
| Die Sätze der durch den Action-Code X gekennzeichneten Dateien bzw. PLAM-Bibliothekselemente werden gemäß dem angegebenen Coded Character Set Namen umcodiert. | |
| CCS=ccsneu | |
| im System gültiger Coded Character Set Name. | ||
| Der Inhalt der Datenobjekte wird mittels XHCS auf den angegebenen CCS umcodiert. | ||
| Falls eine Datei im Katalog bereits mit einen CCS ccsx verknüpft ist, wird angenommen, daß die Sätze in diesem CCS vorliegen und es erfolgt eine Umcodierung in der Form ccsx --> ccsneu | ||
| FCCS=ccsalt | |
| Falls die Datei im Katalog mit keinem CCS verknüpft ist, wird mit FCCS angegeben, in welcher Codierung die Eingabesätze vorliegen. In diesem Fall erfolgt die Umcodierung in der Form ccsalt --> ccsneu | ||
| Dateiinhalte suchen und Treffersätze wegschreiben | |
| ONXFIND 'str' [= W datei] |
| Die Suchzeichenfolge str wird unabhängig von der Codierung auch in UTFxx Dateien gefunden. Dies wird erreicht, indem die UTF codierten Datensätze vor der Suche ohne Datenverlust in den EBCDIC-kompatiblen Zeichensatz UTFE umgesetzt werden. | |
| Treffersätze werden in diesem Code in die Trefferdatei geschrieben. Dies hat zur Folge, daß die alphanumerischen Inhalte im EBCDIC-Umfeld gelesen und ohne Verlust geändert werden können. | |
| Rewrite-Kommando für geänderte Trefferdateien | |
| REWR datei | Beim Zurückschreiben von Treffersätzen in die Originaldateien/Bibliothekselemente wird zuerst geprüft, ob das originale Datenobjekt in einem Unicode-Zeichensatz (UTFxx) vorliegt. Ist dies der Fall, so werden die entsprechenden Treffersätze von UTFE nach UTFxxx umgewandelt und erst danach in das Datenobjekt zurückgeschrieben. |
| Action-Code EDT / Kommando EDT | |
| Falls unter BS2000 7.0 der neue EDT V17.0 eingesetzt ist, kann dieser von CFS mit der erweiterten Funktionalität benutzt werden. Diese beinhaltet: | |
| a) | Dateien mit Satzlängen > 256 Bytes werden automatisch ohne Datenverlust eingelesen und können mit UPD bzw. Write-Kommando zurückgeschrieben werden. | |
| b) | beliebige Dateien im Unicode Format können bearbeitet werden. | |
| Standardmäßig verwendet CFS auch unter BS2000 7.0 den EDT im kompatiblen 16.6-Modus mit allen gegebenen Einschränkungen. Es existiert jedoch ein Kommando zum Einstellen des Verarbeitungsmodus des EDT: | |
| EDTMODE COMP | UNI |
| Vor dem ersten Aufruf des Kommandos / Action-Codes EDT wird festgelegt, ob dieser im kompatiblen Format oder mit der erweiterten Unicode-Funktionalität aufgerufen wird. Der durch das Kommando- bzw. Action-Code benutzte EDT kann somit in unterschiedlichen Modi betrieben werden. Nachdem EDT geladen wurde, ist eine erneute Änderung des Modus für die jeweilige Aufrufart (Kommando/Action-Code) nicht mehr möglich. | |
| Der EDT-Aufrufmodus kann auch im Modul CFSMAIN global für alle Benutzer eingestellt werden. Das Kommando EDTMODE übersteuert diese globale Voreinstellung. | |
| Kommandos zum Modifizieren von Datenobjekten | |
| Erweiterte Editierfunktionen für sequentielle Dateien/Bibliothekselemente | |
| IS [:x: | vsn/device | step] |
| Die am Bildschirm angezeigte SAM-Datei/sequentielles Bibliothekselement wird mit ISAM-Schlüsseln versehen. Dies geschieht durch Umsetzen der ursprünglichen Datei in eine ISAM-Zwischendatei. | |
| Im ISAM-Format können neben der 1 zu 1 Änderung erweiterte Editierfunktionen angewendet werden, wie Kopieren, Einfügen und Löschen von Datensätzen, Einfügen und Löschen von Spaltenbereichen. | |
| Die optionale Angabe eines PVS (:x:) oder einer Privatplatte (vsn/device) bewirkt, daß die Zwischendatei im angegebenen PVS bzw. auf der Privatplatte angelegt wird. Der Parameter :x: bzw. vsn/device wird intern gespeichert und bei allen folgenden Umsetzungen verwendet, sofern keine anderen Angaben gemacht wurden. | ||
| step | Schrittweite für die Generierung der ISAM-Schlüssel. Standardmäßig werden die in der Zwischendatei eingefügten 8 Byte langen Schlüssel mit einer Schrittweite von 100 erhöht. Um sequentielle Dateien mit mehr als 1.000.000 Datensätzen in eine ISAM-Zwischendatei umzuwandeln, sollte im IS-Kommando eine Schrittweite von 10 angegeben werden. | |
| Die Schrittweite wird intern gespeichert und bei allen folgenden Umsetzungen verwendet, sofern keine anderen Angaben gemacht wurden. | ||
| SAM | Rückumsetzen der mit dem Kommando IS bearbeiteten ISAM-Zwischendatei in das sequentielle Datenformat. |
| Das Verlassen des Display-Modus durch Betätigen der K1-/F1-Taste hat die gleiche Wirkung wie das Kommando SAM. Der Benutzer wird gefragt, ob die bearbeitete ISAM-Datei in das SAM-Format zurückübertragen werden soll. Wünscht der Benutzer, daß die ISAM-Datei nicht in das SAM-Format überführt wird, so bleibt die SAM-Datei unverändert und die ISAM-Datei wird nicht gelöscht. | |
| Kleinbuchstaben im Modify-Modus / Suche-Kommando | |
| LOW | CAP | Kleinbuchstaben / Großbuchstaben. |
| LOW | CFS-Editor: Beim Modifizieren wird keine Umwandlung der eingegebenen Kleinbuchstaben in Großbuchstaben vorgenommen. |
| Eingabe von Dateidokumentationen (Action-Code IM): Der Text wird in der eingegebenen Groß-/Kleinschreibung übernommen. | |
| Suche-Kommando, User Option FIND, Variable Action [ONX]FIND: Es erfolgt keine Umwandlung von Kleinbuchstaben im Suchargument in Großbuchstaben. Diese Funktion kann auch durch Eingabe des Sucharguments in der Form L'....' erreicht werden. | |
| Action-Code EDT: Beim Einlesen einer neuen Datei/eines neuen Bibliothekselements wird der LOWER-Modus des EDT unverändert gelassen. Ein bei der Bearbeitung der letzten Datei eingegebenes LOWER ON-Kommando bleibt damit wirksam. | |
| Job-Report Do-Parameter Maske: In Hochkommas eingegebene Parameter werden bezüglich der Groß- Kleinschreibung unverändert an die Prozedur übergeben und nicht, wie dies standardmäßig der Fall ist (CAP), in Großbuchstaben umgewandelt. | |
| CAP | NLOW | CFS-Editor: Beim Modifizieren werden Kleinbuchstaben vor dem Zurückschreiben in die Datei in die entsprechenden Großbuchstaben umgewandelt. |
| Eingabe von Dateidokumentationen (Action-Code IM): Der eingegebene Text wird in Großbuchstaben umgesetzt. | |
| Suche-Kommando, User Option FIND, Variable Action ONXFIND: Suchargumente ([C]'item') werden in Großbuchstaben umgesetzt. | |
| Action-Code EDT: Beim Einlesen einer neuen Datei/eines neuen Bibliothekselements wird der zuvor evtl eingeschaltete LOWER ON-Modus des EDT zurückgesetzt (LOWER OFF). | |
| Job-Report Do-Parameter Maske: In Hochkommas eingegebene Parameter werden in Großbuchstaben umgewandelt. | |
| Anstelle von CAP kann auch das Kommando NLOW oder LOWO (LOW Off) angegeben werden. | |
| Standard: CAP. | |
| Hinweis: LOW bzw. CAP dürfen nicht verkettet mit weiteren Kommandos angegeben werden. Die Kommandofolge LOW;M ist beispielsweise nicht erlaubt. | |
| Datenobjekt zum Ändern freigeben | |
| M | NM | Modify/No Modify. |
| Mit dem Modify-Kommando wird der Inhalt eines mit dem Action-Code D (Display) angekreuzten Datenobjekts (Datei/Jobvariable/Bibliothekselement) zur Änderung freigegeben. Beim Markieren mit dem Action-Code M (Modify) ist das Kommando M automatisch impliziert. Die Modifizierung erfolgt bei Dateien und Jobvariablen sofort nach Betätigen der Datenübertragungstaste. Bei Bibliothekselementen werden die Änderungen bei Verlassen des Modify-Modus zurückgeschrieben. | |
| Der Modify-Modus wird ausgeschaltet durch das Kommando NM (No Modify). | |
| Standardmäßig können sequentielle Dateien und PAM-Dateien im CFS-Editor nur 1 zu 1 modifiziert werden. Für ISAM-Dateien stehen erweiterte Editierfunktionen zur Verfügung. Diese sind im Abschnitt "Editieren von ISAM-Dateien beliebigen Formats" beschrieben. Auch sequentielle Dateien können im ISAM-Format mit diesen erweiterten Funktionen editiert werden. Mehr hierzu auf Seite 8-. | |
| Hinweise: | |
| Beim Modifizieren von Daten mit CFS darf die Taste "Ausfügen Zeichen" nicht benutzt werden, da sich hierdurch der gesamte am Bildschirm angezeigte Dateninhalt verschiebt. | |
| Beim Modifizieren im Hexadezimalmodus können Zeichen auch in Character Darstellung eingegeben werden. Hierbei ist das gewünschte Zeichen im ersten Halbbyte einzugeben. An der Stelle des zweiten Halbbytes ist ein Leerzeichen anzugeben. Beispiel: Zur Eingabe des Zeichens 'F' (X'F6') kann der ursprünglich an dieser Stelle stehende Hexadezimalwert CA durch F_ überschrieben werden. Es ist damit auch möglich, Kleinbuchstaben im Hexa-Modus einzugeben. Dazu muß jedoch der LOW-Modus eingeschaltet sein. | |
| Es ist zu beachten, daß im Unterschied zum EDT, Kleinbuchstaben im CAP-Modus von CFS (siehe oben) als solche dargestellt werden; eingegebene Kleinbuchstaben werden im Standardmodus CAP in Großbuchstaben umgesetzt. | |
| An einem Datensichtgerät mit deutscher Tastatur werden im Gegensatz zu früheren CFS-Versionen folgende Zeichenumwandlungen im CAP-Modus nicht durchgeführt: | |
| '{' ( 'ä' ) --> '[' ( 'Ä' ) | ||
| '|' ( 'ö' ) --> ' ' ( 'Ö' ) | ||
| '}' ( 'ü' ) --> ']' ( 'Ü' ) | ||
| Zum Verkürzen von Jobvariablen muß zuerst der LOW-Modus (siehe oben) eingestellt werden. Anschließend sind die zu löschenden Daten der Jobvariablen (rechtes Ende der relevanten Daten) mit NIL-Zeichen zu ersetzen. D.h. es ist die AFG-Taste (Ausfügen) solange zu betätigen, bis der zu löschende Text und alle Zeichen rechts davon durch NIL-Punkte ersetzt sind. | |
| Beim Modifizieren von ISAM-Dateien werden die Stellen vom Ende des Datensatzes bis zum Ende der Bildschirmzeile mit überschreibbaren Nil-Zeichen gefüllt. Die Datensätze können somit durch Überschreiben der Nil-Zeichen über das bisherige Satzende hinaus erweitert werden. | |
| Das Verkürzen eines Datensatzes durch Überschreiben mit NIL-Zeichen ist nicht möglich. | |
| Kommandos zum Anzeigen von Datenobjekten | |
| Verschieben des Sichtfensters horizontal/vertikal | |
| + | - | Sichtfenster um einen Bildschirm weiter zum Ende/Anfang verschieben. |
| Neben "+" führt auch das leere Kommandofeld (abgesendet mit ENTER) auf den nächsten Bildschirm. | |
| ++ | -- | Sichtfenster auf Ende/Anfang der Datei positionieren. |
| Hinweise: | |
| Das Positionieren an das Ende einer sehr großen SAM-Datei kann wesentlich beschleunigt werden. Anstelle von ++ ist hierzu das Kommando PPnnnn (Position to Pam-Block, siehe Seite 8-) anzugeben. nnnn ist hier die Nummer des letzten Datenblocks (LASTP-Angabe). Die Satznummerierung geht in diesem Falle verloren. | |
| Während der normalen Positionierung an das Ende einer sehr großen SAM-Datei (++) kann es zu längeren Wartezeiten kommen, da die Datei von CFS vollständig gelesen werden muß. Ein Abbrechen dieses Vorgangs wird erreicht durch Betätigen der K2-Taste (Verzweigen in den Kommando-Modus des BS2000) und anschließendes /INTR R Kommando. Das Sichtfenster wird in diesem Fall auf die zuletzt gelesene Stelle in der Datei positioniert. | |
| Bei PAM-Dateien kann mit ++ nur bis zum letzten beschriebenen Datenblock positioniert werden. Unter TSOS kann im Display-Modus auch auf die PAM-Seiten jenseits des Last-Page Pointers positioniert werden. | |
| +n | -n | Sichtfenster um n Sätze weiter zum Ende/Anfang verschieben. |
| > | < | gleiche Wirkung wie R/L. |
| RR | LL | Sichtfenster zum Satzende/Satzanfang positionieren. |
| Bei Sätzen unterschiedlicher Länge ist jeweils der erste, am Bildschirm angezeigte Satz maßgebend. | |
| >> | << | gleiche Wirkung wie RR/LL. |
| R n | L n | Sichtfenster um n Stellen nach Rechts/Links verschieben. |
| >n | <n | gleiche Wirkung wie R n/L n. |
| R X'hex' | L X'hex' | >X'hex' | <X'hex' |
| Sichtfenster um X'hex' Stellen nach Rechts / Links verschieben. | |
| C n | Sichtfenster auf Spalte n positionieren. Satzanfang = C1. |
| CX'hex' | Sichtfenster auf Spalte X'hex' positionieren. Satzanfang = CX'0'. |
| Hinweis: | |
| Als Alternative zur horizontalen Verschiebung des Bildschirmfensters sei auf das Kommando AD (Arrange Data) hingewiesen. Dieses Kommando ermöglicht die selektive Anzeige bestimmter Spaltenbereiche einer Datei. Die Reihenfolge der Spalten und deren Länge ist frei bestimmbar. Für jeden ausgewählten Spaltenbereich kann ein Darstellungsformat (Character/Hexadezimal) gewählt werden. | |
| Spaltenbereiche für die Anzeige auswählen/umorganisieren | |
| AD { [col | konst | seq] ["text"] } {, ... } ... [, FC= X'cc' | C'c'] |
| Arrange Data. Der Anzeigemodus der Display-Datei wird dahingehend verändert, daß nur bestimmte Spaltenbereiche der Datensätze ausgewählt und in einer festgelegten Reihenfolge am Bildschirm dargestellt werden. Zwischen den Spaltenbereichen können konstante Strings eingefügt werden. Die Darstellung jeder einzelnen Spalte kann in character und hexadezimaler Form erfolgen. Zu den ausgewählten Spaltenbereichen können Beschreibungstexte für die Überschriftszeile (Scale) definiert werden. Durch das Kommando AD wird ausschließlich die Darstellung der in der Display-Datei gespeicherten Datensätze beeinflußt. Die Datei selbst bleibt unverändert bestehen. | |
| Ein evtl. aktiver Offset-Modus für die Datei (z.B. O-4) wird durch das AD-Kommando zurückgesetzt. | |
| col | Angabe des auszuwählenden Spaltenbereichs. Es sind zwei verschiedene Darstellungsweisen möglich. | |
| :col1: len [ B[S] | C | H | P[n] | Z | STCK] | ||
| Anfangsspalte des auszuwählenden Bereichs. Die Spaltenzählung beginnt mit 1. | ||
| Es kann auch eine negative Spaltenangabe gemacht werden ( :-col1: ). Damit kann z.B. das Längenfeld eines Satzes mit variabler Länge angezeigt werden: :-4:2B bzw. :-4:4X | ||
| len | ||
| Länge des Spaltenbereichs. | ||
| :col1-col2: [B[S]|C|H|P[n]|Z|STCK] | ||
| Definition des Spaltenbereichs durch die Anfangs- und Endespalte. Als Endespalte (col2) kann auch das Zeichen $ (= Satzende) angegeben werden. | ||
| Beispiel: :1-20: Es wird der Bereich von Spalte 1 bis Spalte 20 ausgewählt. Äquivalent hierzu ist die Angabe der Anfangsspalte :1: und der Länge 20 (:1:20). | ||
| B[S] | Im ausgewählten Spaltenbereich steht eine Binärzahl mit (BS) oder ohne Vorzeichen (B). Die Länge des Spaltenbereichs darf nur 1, 2, 3 oder 4 betragen. | |
| C | Ausgabe des Spaltenbereichs im Characterformat (Standard). | |
| H | Ausgabe des Spaltenbereichs im hexadezimalen Format. H bewirkt einen auf die Spalte bezogenen Hexadezimalmodus (siehe Display-Kommando H/NH). Anstelle von H kann auch X angegeben werden. | |
| P[n] | Im ausgewählten Spaltenbereich steht eine gepackte Zahl mit oder ohne Vorzeichen. | |
| n | Anzahl der Kommastellen. Standard: n = 0 | |
| Beispiel: :35-38:P2 liefert z.B. folgendes Zahlenformat: 99999,50 | ||
| Z | Im ausgewählten Spaltenbereich steht eine Dezimalzahl mit Vorzeichen. Eine Zahl des Formats Z entspricht in COBOL der Definition "PIC S9" und ist hexadezimal in folgender Form gespeichert: FaFb ... FnZm. Hierbei stehen a, b, ... ,n, m für Ziffern 0, ..., 9. Z enthält das Vorzeichen der Zahl: Die Sedezimalzeichen A, C, E, F stehen für positive und B, D für negative Werte. | |
| Beispiel: F1C2 entspricht +12, F1D2 entspricht -12 | ||
| STCK Im ausgewählten Spaltenbereich steht eine binär im STCK (Store Clock) Format gespeicherte Datums- und Zeitangabe. Das STCK-Feld kann vier oder acht Bytes lang sein. In der Ausgabe wird das Feld in der Form YYYY-MM-DD HH:MM:SS:MMMMMM angezeigt. MMMMMM entspricht hierbei dem Milli- und Mikrosekundenwert der Zeitangabe. | |
| Standard: Die Spalte wird im Characterformat angezeigt. | |
| konst | Konstanter String, der in der aufbereiteten Satzdarstellung vor der nächsten Spalte, bzw. nach der zuletzt ausgewählten Spalte eingefügt wird. | |
| [len] C'string' | X'string' | |
| len | |
| Gesamtlänge der Konstanten. Der in Form von C'...'/X'...' angegebene String wird solange wiederholt, bis die gewünschte Länge erreicht ist. | |
| Standard: len = Länge des angegebenen Strings. | |
| C'string' | X'string' | |
| Wert der einzufügenden Konstanten. C'string' kann zu 'string' abgekürzt werden. | |
| seq | Sequentielle Nummerierung. Bei SAM- und PAM-Dateien wird ein fortlaufendes Numerierungsfeld in die Anzeige eingefügt. | |
| Bei ISAM-Dateien ist eine korrekte Ausgabe der Nummerierung nur garantiert, falls vom Anfang der Datei aus ein Write-Kommando oder ein Suche-kommando mit Wegschreiben der Treffer ausgeführt wird. | ||
| Falls mehrere SEQ-Einfügungen in einem Datensatz vorgenommen werden, muß für alle SEQ-Anweisungen die gleiche Länge und Stepsize angegeben werden. | ||
| SEQ(len [, step]) | |
| len | |
| Länge des Numerierungsfeldes. 1 <= len <= 10. | |
| step | |
| Schrittweite der Numerierung. 1 <= step <= 30000. | |
| Standard: 1 | |
| "text" | Der angegebene Text definiert eine Spaltenüberschrift, die in der Scale-Zeile des Display-Bildschirms angezeigt wird. | |
| Es können beliebig viele Spalten-/Konstantenbereiche aneinandergereiht werden. Die einzelnen Bereiche werden durch Kommas getrennt. Die ausgewählten Spalten /Konstanten werden in der Darstellung lückenlos aneinandergereiht. Mit dem Kommando AD können auch Spalten dupliziert oder vertauscht werden. | |
| FC= | Fill-Character. Spaltenbereiche, die ganz oder teilweise außerhalb eines Datensatzes liegen, werden mit diesem Zeichen aufgefüllt. Ausnahme: Der letzte Spaltenbereich wird nicht aufgefüllt, sondern entsprechend der Länge der vorhandenen Daten verkürzt. Für weitere Einzelheiten siehe Hinweise. | |
| Standard: FC=C' '. | ||
| NAD | AD-Modus ausschalten. Die Datensätze werden im Originalformat angezeigt. |
| Standard: NAD | |
| AD | Die mit dem letzten AD-Kommando definierte Spaltenauswahl wird wieder aktiviert. |
| AD? | AD?,%name |
| Die mit dem letzten AD-Kommando definierte Spaltenauswahl / eine mit dem Kommando SP %name in einem Parameter-Set gesicherte Spaltenauswahl wird angezeigt. Beschreibung von SP %name siehe unten. | |
| AD ( ) | Durch () wird eine spezielle Bildschirmmaske angefordert. In dieser stehen dem Benutzer 18 Zeilen zur Eingabe umfangreicher Spaltendefinitionen zur Verfügung. Diese sind lückenlos, d.h. ohne Blanks einzugeben. |
| Durch Betätigung der ENTER-Taste wird der AD-Modus aktiviert. Die K1-Taste bewirkt den Abbruch des AD-Kommandos. Mit der F3-Taste kann die ausgefüllte Maske in einer von CFS angelegten Hardcopy-Datei protokolliert werden. Ansonsten wirkt F3 wie ENTER. | |
| Im Kommandofeld der Maske können BS2000-Kommandos sowie das SP-Kommando eingegeben werden. | |
| SP %name [, jrsave] |
| Save Parameters. Mit diesem Kommando werden die in der AD-Maske ( AD,() ) eingetragenen Spaltenauswahl Definitionen unter einem Namen in der Datei CFS.JRSAVE [.jobname] bzw. in einer mit /FILE datei,LINK=JRSAVE zugewiesenen Datei gesichert. Die genaue Regel, nach der der Name der JRSAVE-Datei gebildet wird, ist auf Seite 27- unter CFS.JRSAVE beschrieben. | |
| %name | ein- bis 44-stelliger alphanumerischer Name für den Parameter-Set. | |
| jrsave | Name der JRSAVE-Datei. Der Dateiname sollte nur angegeben werden, wenn die Parameter in eine andere als die von CFS standardmäßig verwendete JRSAVE-Datei (siehe oben) gesichert werden. | |
| Der Benutzer kann eine mit SP gesicherte Spaltenauswahl durch die Kommandos AD %name bzw. AD?,%name aktivieren/anzeigen lassen. | |
| AD %name | %? |
| Es wird die Spaltendefinition aktiviert, die zu einem früheren Zeitpunkt mit dem Kommando SP %name in einem Parameter-Set gesichert wurde. | |
| Die Inhalte der in der SET-Maske aufgeführten Parameter werden mit den in dem Parameterset %name gespeicherten Angaben modifiziert. Die Ausgabe der SET-Maske wird unterdrückt. | |
| %?: Es werden alle in Frage kommenden Parametersets in einer Maske angezeigt. Durch Ankreuzen kann einer der vorgeschlagenen Parametersets ausgewählt werden. | ||
| AD (dat) | (bibl ([t/] elem) ) |
| Die Spaltendefinitionen sind in einer sequentiellen Datei dat oder in einem Bibliothekselement gespeichert. Falls bei einem Bibliothekselement der Elementtyp nicht angegeben ist, wird S/ ergänzt, sofern es sich um eine PLAM-Bibliothek handelt. | |
| Format der AD-Parameterdatei dat: | ||
| Jeder Datensatz beschreibt eine oder mehrere Spaltendefinitionen. Die einzelnen Definitionen sind durch Kommas zu trennen. Am Satzende darf kein Komma angegeben werden. Die maximale Länge von 250 Bytes pro Satz sollte nicht überschritten werden. | ||
| Beispiele: | |
AD :21:30
| |
| Von den Datensätzen der Display-Datei wird nur der Teil ab Spalte 21 in der Länge von 30 Bytes angezeigt. Bei Datensätzen mit einer kleineren Länge wird die Darstellung der Spalte entsprechend verkürzt. | |
AD :21-40:"<-- SPALTE 21-40 -->",:1:20"<-- SPALTE 1-20 --->",4X'FF'
| |
| Die Darstellung beginnt mit Spalte 21 bis 40 der in der Display-Datei gespeicherten Sätze. Entsprechendes wird auch in der Scale-Zeile angezeigt ("..."). Falls Datensätze kürzer als 50 Bytes sind, so wird der fehlende Bereich in der Darstellung mit Blanks (C' ') aufgefüllt. Mit dem zweiten, im AD-Kommando angegebenen Parameter wird Spalte 1 bis 20 der Datensätze ausgewählt. Der dritte Parameter bewirkt, daß die Satzdarstellung im Display mit der Konstanten X'FFFFFFFF' abgeschlossen wird. | |
AD (AUSW)
| |
| Von den Datensätzen der Display-Datei werden die in der Datei AUSW hinterlegten Spaltenbereiche ausgewählt und am Bildschirm dargestellt. | |
| Die Datei AUSW habe folgenden Inhalt: | |
|
:35-38:"TSN",' ' :45:8"PROGRAMM",' ' :30:10"ISAM-KEY",' ' ........ :100-$:"SATZ-REST" |
| Auf den Bereich von Spalte 35 bis 38 folgt ein Blank. Danach Spalte 45 bis 52 und wieder ein Blank usw. Die ausgewählten Daten werden durch entsprechende Bezeichnungen in der Scale-Zeile beschrieben. | |
| Hinweise: | |
| Falls auf eine bereits im AD-Modus dargestellte Datei ein neues AD-Kommando angewendet wird, so ist zu beachten, daß sich die Spaltenangaben auf das Originalformat der Datensätze und nicht auf das durch AD dargestellte Satzformat beziehen. | |
| Der AD-Modus gilt jeweils nur für die im Display befindliche Datei. Bei einem Wechsel zur nächsten Display-Datei mit dem Kommando NF (Next File) bzw. D wird der AD-Modus ausgeschaltet. Durch das Kommando AD ohne Operanden kann die zuletzt definierte Spaltenauswahl jederzeit wieder aktiviert werden. | |
| Bei der Angabe eines Spaltenbereichs in der Form :col1-col2: kann für col2 auch das Zeichen '$' angegeben werden. $ steht hierbei für die jeweils letzte Spalte des Datensatzes. Durch die Angabe :101-$: wird z.B. der Bereich von Spalte 101 bis zum Satzende ausgewählt. Eine Spaltendefinition der Art :col1-$: kann nur als letzte angegeben werden. | |
| Wird durch :col1-col2: bzw. :col1:len ein Spaltenbereich definiert, der länger als ein bestimmter Datensatz ist, so sind zwei Fälle zu unterscheiden: | |
| a) | Der angegebene Spaltenbereich ist nicht der letzte. | |
| Die im Datensatz fehlenden Stellen werden durch ein festgelegtes Füllzeichen (Standard: C' ') aufgefüllt. | ||
| b) | Der angegebene Spaltenbereich ist der letzte in der Definition. | |
| Der Spaltenbereich wird nur in der Länge der im Satz vorhandenen Daten ausgegeben. | ||
| Im AD-Kommando können Spalten auch mehrfach ausgewählt werden. Die Länge der angezeigten Daten kann dadurch auf ein Vielfaches der ursprünglichen Satzlänge anwachsen. Es ist jedoch zu beachten, daß die maximale Länge von 32000 Stellen nicht überschritten wird. | |
| Ist die Display-Datei vom Fcbtyp ISAM, so ist zu beachten, daß in der Spaltenauswahl ein Bereich enthalten sein muß, der den ISAM-Schlüssel oder einen Teil vom Beginn des ISAM-Schlüssels umfaßt. | |
| Die durch das AD-Kommando ausgewählten und am Bildschirm dargestellten Daten werden wie normale Sätze einer Datei behandelt. Im AD-Modus sind alle Display-Kommandos, wie DS/DW/HEX/R/L/C sowie M (Modify) und S (Suchen) erlaubt. Mit dem Kommando W (Write) werden die Datensätze mit dem im Display dargestellten Format in eine andere Datei übertragen. Bei ISAM-Dateien wird dabei auch die aktuell im Display geltende Position des ISAM-Schlüssels (s.o.) übernommen. | |
| Falls eine Spalte mehrfach ausgewählt und im Modify-Modus Daten geändert wurde, so ist zu beachten, daß die Änderung nur dann in die Datei zurückgeschrieben wird, falls sie in der letzten, d.h. in der am weitesten rechts vorkommenden Auswahl der Spalte vorgenommen wurde. | |
| Die Kommandos AD und W in Kombination können dazu benutzt werden, eine Datei zu erstellen, bei der gegenüber dem Original zwei Spaltenbereiche vertauscht sind. Durch das unten angegebene AD-Kommando werden in der Darstellung die Spalten 21-30 und 41-50 getauscht. Mit dem Write-Kommando werden die dargestellten Daten in die Datei CFS.SP.TAUSCH geschrieben. | |
AD :1-20:,:41-50:,:31-40:,:21-30:,:51-$:
| |
W9999,CFS.TAUSCH
| |
| Handelte es sich bei der ursprünglichen Datei um eine ISAM-Datei mit KEYPOS=25, KEYLEN=8 und RECFORM=V, so wird CFS.TAUSCH ebenfalls als ISAM-Datei, jedoch mit KEYPOS=45, KEYLEN=8 angelegt. Eine Verschiebung des ISAM-Schlüssels wird beim Anlegen einer neuen Datei durch das Write-Kommando berücksichtigt. | |
| Durch die H-Option bei der Definition der Spalten ist es möglich, in der gleichen Bildschirmdarstellung hexadezimale und Character-Daten zu mischen. Wird bei einer mit dem Zusatz H bzw. X versehenen Spaltendefinition die Hexadezimaldarstellung aktiviert, so können die Daten dieser Spalte im Modify-Modus auch hexadezimal verändert werden. Andere Spalten, die ohne den Zusatz H definiert wurden, können im gleichen Eingabeschritt im Character-Modus geändert werden. | |
| Display-Datei nach jeder Maskeneingabe schließen | |
| Standard: NCA | |
| Hinweise: | |
| Beim Modifizieren von Dateien (Modify) bleibt der CA-Modus ohne Wirkung. D.h. die zur Änderung freigegebene Datei bleibt bis zum Verlassen des Modify-Modus gegen Schreibzugriff durch andere Benutzer geschützt. Der CA-Modus ist ebenfalls ohne Wirkung bei der Einzelsatzdarstellung (Single Record-Modus, SR), sowie beim Display von Banddateien. | |
| Der CA-Modus wird mit dem Verlassen des Display-Modus nicht ausgeschaltet, sondern wirkt auch für alle folgenden Display-Aktionen solange bis er durch das Kommando NCA wieder zurückgenommen wird. | |
| Nächste Display-Datei anzeigen | |
| D | Display Next File. Das nächste mit dem Action-Code D oder M markierte Datenobjekt wird angezeigt. Anstelle von D kann auch NF angegeben werden. |
| Art des Datenzugriffs auf Datei festlegen | |
| DA typ [, param ] |
| Mit diesem Kommando kann ein alternativer Datenzugriff auf die aktuell im Display befindliche Datei festgelegt werden. Dies bedeutet, daß die Datensätze in einer anderen Sortierreihenfolge bzw. in einem anderen Datenformat angezeigt werden. | |
| typ | Art des Datenzugriffs. Gegenwärtig sind folgende Zugriffsarten realisiert: | |
| I | Zugriff auf eine NK-ISAM Datei gemäß einem mit CREate-Alternate-Index eingerichteten Sekundärschlüssel. | |
| CCS | Der Dateiinhalt wird für die Anzeige von dem angegebenen (vermuteten) Character-Set in den Terminalcode umgewandelt. Damit kann man bei unbekannter Kodierung (kein CCS im Katalog) testen, in welchem Zeichensatz die Datei erstellt wurde. | |
| DACCS ohne Parameter wandelt den Dateiinhalt zur Anzeige aus dem im CCS-Feld des Katalogs hinterlegten Code in den Terminalcode um. | ||
| CODE | Zeichenweises Konvertieren der Datensätze/Datenblöcke für die Bildschirmdarstellung. Die Datensätze in der Datei werden nicht verändert. | |
| FLAM | Zugriff auf eine mit dem Softwareprodukt FLAM komprimierte Datei. Die Datensätze werden im Originalformat, d.h. unkomprimiert angezeigt. | |
| param | Zusatzparameter für den Datenzugriff. Je nach Art des Datenzugriffs (CCS/CONV/I/FLAM) hat der Parameter verschiedene Bedeutungen: | |
| CCS [,ccsname] | |
| CODE {, UPPER | UPPER2 | LOWER | EBCTOASC | ASCTOEBC | datei} [, K=Y] | |
| UPPER Umsetzung aller Kleinbuchstaben in Großbuchstaben. | |||
| X'00' --> X'00' (unverändert) | |||
| X'4F' (ö bzw. |) --> X'4F' (unverändert) | |||
| X'FB' (ä bzw. {) --> X'FB' (unverändert) | |||
| X'FD' (ü bzw. }) --> X'FD' (unverändert) | |||
| UPPER2 Umsetzung aller Kleinbuchstaben in Großbuchstaben. | |||
| X'00' --> X'40' (Blank) | |||
| X'4F' (ö bzw. |) --> X'BC' (Ö bzw. ~) | |||
| X'FB' (ä bzw. {) --> X'BB' (Ä bzw. [) | |||
| X'FD' (ü bzw. }) --> X'BD' (Ü bzw. ]) | |||
| LOWER Umsetzung aller Großbuchstaben in Kleinbuchstaben. | |||
| X'40' --> X'40' (unverändert) | |||
| X'BC' (Ö bzw. ~) --> X'BC' (unverändert) | |||
| X'BB' (Ä bzw. [) --> X'BB' (unverändert) | |||
| X'BD' (Ü bzw. ]) --> X'BD' (unverändert) | |||
| ASCTOEBC Umsetzung von ASCII Zeichen nach EBCDIC. | |||
| EBCTOASC Umsetzung von EBCDIC Zeichen nach ASCII. | |||
| datei Umsetzung gemäß einer benutzereigenen Tabelle. Die Umsetztabelle ist in der angegebenen Datei (SAM, Recform=V) definiert. Die Datei enthält 16 Datensätze entsprechend den umzusetzenden Codepositionen 00 - 0F (Satz 1), 10 - 1F (Satz 2), ..., F0 - FF (Satz 16). Jeder Datensatz ist 16 oder 32 Byte lang. Bei 32 Byte werden die Daten als hexadezimale Codierungen interpretiert. Bei 16 Byte werden die Daten als direkte Character Codierungen interpretiert. | |||
| K=Y Bei ISAM-Dateien sollen auch die Daten des Schlüssels konvertiert werden. Standardmäßig werden die ISAM-Schlüssel von der Konvertierung ausgenommen. | |||
| Eine neue Datei, die tatsächlich die umgesetzten Zeichen enthält, kann mit dem Kommando W$,datei erzeugt werden. | |
| I | Beim ISAM-Zugriff wird mit diesem Parameter der gewünschte Alternate Index angegeben. Die Datensätze werden aufsteigend gemäß dem Alternate Index angezeigt. | |
| FLAM Bei der Option FLAM können Parameter angegeben werden, die die Art der Dekomprimierung beeinflussen, z.B. DAFLAM,TR=A/E. Durch diesen Parameter werden die Daten bei der Dekomprimierung vom ASCII- in den EBCDIC-Zeichensatz umgesetzt. Für eine ausführliche Beschreibung aller Parameter siehe "FLAM-Benutzerhandbuch". | |
| NDA | Die Datenzugriffsart wird auf die Standardeinstellung zurückgesetzt. |
| Hinweise: | |
| Mit dem DA-Kommando können auch benutzerspezifische Zugriffe auf Datenbanken realisiert werden. Eine detaillierte Beschreibung des Data Access Interface ist auf Wunsch verfügbar. | |
| Durch das W-Kommando können die Datensätze in der dargestellten Reihenfolge bzw. in dem dargestellten Format (d.h. bei FLAM entkomprimiert) in eine andere Datei geschrieben werden. Bei DA I,key wird in der durch Write erzeugten ISAM-Datei die Keypos und Keylen des gerade aktivierten Sekundärschlüssels verwendet. | |
| Bei der hexadezimalen Anzeige (Kommando H) werden die Daten anders als bei EDT oder Show-File nicht in der Originalkodierung angezeigt. CFS zeigt die hexadezimalen Daten bei eingeschaltetem DA-Modus in dem internen Code EDF01 an. | |
| Ein durch das Kommando DA festgelegter alternativer Datenzugriff auf die Display-Datei gilt solange, bis der Display-Modus durch die K1-Taste bzw. die Kommandos D/NF/LF/LST für die aktuelle Datei beendet wird. Während des Display kann durch das Kommando NDA in die Standardzugriffsmethode umgeschaltet werden. | |
| Display (Edit) Long | |
| DL [,NC] | NDL | Display Long/No Display Long. |
| DL [, NC] | Jeder Datensatz wird in seiner ganzen Länge bzw. bis Bildschirmende angezeigt. |
| Anstelle von DL können auch die Kommandos EL (Edit Long) oder DW (Display Wide) angegeben werden. | |
| NDL | Es wird von jedem Datensatz nur soviel angezeigt, wie in eine Bildschirmzeile paßt. |
| Anstelle von NDL können auch die Kommandos ELO (Edit Long Off) oder DS (Display Short) angegeben werden. | |
| Standard: NDL. | |
| Hinweis: | |
| Als Alternative zur Dateidarstellung im DL-Modus sei auf das Kommando AD (Arrange Data, Seite 8-) hingewiesen. Dieses Kommando ermöglicht die selektive Anzeige bestimmter Spaltenbereiche einer Datei. Die Reihenfolge der Spaltenbereiche und deren Länge ist frei bestimmbar. Für jeden ausgewählten Spaltenbereich kann ein Darstellungsformat (Character/Hexadezimal) gewählt werden. | |
| Hexadezimale Darstellung | |
| H | NH | Hexadezimal display/No Hexadezimal display. |
| Anstelle von H/NH können auch die Kommandos HEX/HEXO angegeben werden. | |
| Standard: NH. | |
| Hexadezimale Spaltendarstellung | |
| HEXC | NHEXC | Hexadezimale Spaltendarstellung/dezimale Spaltendarstellung. |
| Bei Hexadezimal-Darstellung erfolgt die Anzeige der Spaltenposition im EL-Modus (Edit Long) am linken Rand des Bildschirms in dezimalen Zahlen, z.B. (0025) Durch das Kommando HEXC werden die Spalten in hexadezimalen Werten angezeigt, z.B. (0018). Im Dezimalmodus ist 1 die erste Spalte. Im Hexadezimalmodus beginnt die Spaltenzählung mit 0. Siehe hierzu auch Kommando CX'..'. | |
| Standard: NHEXC. | |
| Anzeigemodus festhalten | |
| KDO | NKDO | Keep Display Options/do Not Keep Display Options. |
| Im Normalfall (NKDO) werden die verschiedenen Optionen der Darstellung von Daten beim Beenden des Display-Modus bzw. beim Übergang zur Anzeige einer anderen Display-Datei auf die Standardwerte zurückgesetzt. | |
| Das Kommando KDO bewirkt, daß die aktuellen Werte der folgenden Parameter festgehalten und beim Anzeigen einer neuen Datei im Display-Modus automatisch aktiviert werden: | |
| Cnn | erste angezeigte Spalte | ||
| DL/DS | Display Long/Display Short | ||
| H/NH | Hexadezimale/Character-Darstellung | ||
| N/NN | Satznummern anzeigen/nicht anzeigen | ||
| OL/NOL | Zeilenlineal anzeigen/nicht anzeigen | ||
| SR/NSR [SHARUPD=YES] Einzelsatzdarstellung/SHARUPD=YES | ||
| Standard: NKDO. | |
| Hinweis: | |
| Die gewünschten Display-Modi können bereits beim Start von CFS über eine Startup-Datei (siehe Seite 20-) eingestellt und für den aktuellen CFS-Lauf als Standardwerte festgehalten werden. Die Startup-Datei könnte z.B. folgendes Aussehen haben: | |
|
*002 FILE=NO NSR SHARUPD=YES DL N KDO *DIA | |
| Die mit KDO festgehaltenen Display-Optionen gelten bis zur Beendigung des Programms CFS. | |
| Letzte Display-Datei wieder anzeigen | |
| LF | Last File. Das vorhergehende Display-Datenobjekt wird wieder angezeigt. |
| Aus dem Display zur Anzeige der Dateienliste zurückkehren | |
| LST | LiSTe. Wieder zur Anzeige der Dateienliste zurückkehren. |
| Hinweis: | |
| Anstelle des Kommandos LST kann auch die K1-/F1-Taste zur Rückkehr in die Dateienliste verwendet werden. Die F1-Taste hat dabei den Zusatzeffekt, daß Änderungen im Modify-Modus in die Datei zurückgeschrieben werden, selbst wenn diese im gleichen Dialogschritt wie die Betätigung der F1-Taste vorgenommen wurden. | |
| Anzeige der Satz-/Blocknummern | |
| N | NN | record Numbers/No record Numbers. |
| Bei SAM-Dateien werden die Satznummern angezeigt/nicht angezeigt. | |
| Bei PAM-Dateien werden die Blocknummern angezeigt/nicht angezeigt. | |
| Standard: N (Satz-/Blocknummern werden angezeigt). | |
| Nächste Display-Datei anzeigen | |
| NF | Next File. Das nächste mit dem Action-Code D oder M bezeichnete Datenobjekt wird angezeigt. Anstelle von NF kann auch D angegeben werden. |
| Hinweis: | |
| Hat der Benutzer in einer Dateienliste mehrere Datenobjekte mit D bzw. M gekennzeichnet, er möchte diese jedoch nicht in der Reihenfolge der markierten Dateien innerhalb der Liste angezeigt bekommen, sondern z.B. die dritte Datei zuerst, so kann er gleichzeitig mit dem Senden der Action-Codes das Kommando NF mehrmals verknüpfen (z.B.: D;NF;NF) und erhält dann die der Anzahl des Kommandos NF (oder D) entsprechende Datei im Display. | |
| Satzanfang für Display festlegen/ändern | |
| O [x] n | Spalte +/-n wird in Zukunft als logischer Satzanfang betrachtet. |
| x | + | - (Standard: +) | |
| n | 0 - 999 | |
| O 0 | Der Offset für die Dateianzeige wird auf den Standardwert zurückgesetzt. |
| Beispiele: | |
O-4
| |
| Alle Datensätze einer RECFORM=V Datei werden einschließlich Satzlängenfeld angezeigt. Die Spaltenangabe C1 (Column 1) bezieht sich in diesem Fall auf den Beginn des Satzlängenfeldes und nicht auf den Beginn der Daten. | |
| Mit S,:1:>X'0054' können nach Eingabe von O-4 alle Datensätze gesucht werden, die mehr als 80 Datenbytes enthalten (Satzlänge > 80 + 4). | |
O+8
| |
| Bei ISAM-Dateien mit KEYPOS=5,KEYLEN=8 werden die ISAM-Schlüssel nicht angezeigt. Die Spaltenangabe C1 (Column 1) bezieht sich in diesem Fall auf die Stelle nach dem ISAM-Schlüssel und nicht auf den Beginn des ISAM-Schlüssels, wie dies standardmäßig der Fall ist. | |
| Sichtfenster auf Satz/Datenblock positionieren | |
| Pn | SAM/PAM: Sichtfenster auf Satz/Block mit der angegebenen Nummer positionieren. Anstelle von Pn kann auch das Kommando #n angegeben werden. |
| Hinweis: | |
| Bei PAM-Dateien kann nur bis zum letzten beschriebenen Datenblock positioniert werden. Nur unter TSOS werden auch die der Datei zugewiesenen, jedoch noch nicht beschriebenen PAM-Blöcke im Display angezeigt. | |
| Pkey | PX'hex' | ISAM: Sichtfenster auf Satz mit dem angegebenen ISAM-Schlüssel positionieren. |
| Anstelle von Pkey/PX'key' kann auch #key/#X'key' angegeben werden. | |
| PBnnn | Bei SAM-Dateien: Position to Buffer. |
| Bei PAM-Dateien mit BLKSIZE=(STD,1): Position to PAM-Block. | |
| Bei PAM-Dateien mit BLKSIZE > (STD,1): Position to logical PAM-Buffer. | |
| Das Sichtfenster wird auf den logischen Puffer mit der angegebenen Nummer positioniert. Die Anzeige beginnt mit dem ersten Satz im angegebenen Puffer. Die Größe des Datenpuffers bei SAM-Dateien hängt ab von der Blocksize der Datei und ist ein Vielfaches von 2048 Bytes. Anstelle von PBnnn kann auch #Bnnn angegeben werden. | |
| Hinweise: | |
| Das PB-Kommando bietet bei sehr großen SAM-Dateien die Möglichkeit, das Sichtfenster bedeutend schneller als mit dem normalen Kommando ++ an das Dateiende zu positionieren, da bei PB direkt der entsprechende Block gelesen wird. | |
| Beim Positionieren auf SAM-Puffer verliert CFS die Kontrolle über die Satznummern. Es wird daher automatisch auf den NN-Modus (No Numbers) umgeschaltet. | |
| PPnnn | Position to Pam-Block. |
| Falls die Datei eine BLKSIZE = (STD,b) besitzt, so wird das Sichtfenster durch PPnnn auf den PAM-Block INTEGER(nnn/b) positioniert. | |
| Anzeigeposition merken/Dateiausschnitt an vorher gemerkte Position | |
| verschieben | |
| PD.n | Position Define. Die Position des angezeigten Dateiausschnitts wird zum Zwecke des späteren Zurückpositionierens gemerkt. |
| n | Ziffer zwischen 0 und 9. | |
| P.n | Positionieren an definierte Stelle: Das Display springt an die Stelle in der Datei, die zuvor mit einem PD-Kommando definiert wurde. |
| n | Ziffer zwischen 0 und 9. | |
| SAM-/ISAM-Datei im PAM-Format anzeigen | |
| PAM | NPAM | PAM-Format/No PAM-Format. |
| PAM | SAM-/ISAM-Dateien werden im PAM-Format dargestellt. |
| NPAM | Der PAM-Modus für SAM-/ISAM-Dateien wird ausgeschaltet. |
| Standard: NPAM. | |
| Hinweis: | |
| PAM-Dateien werden stets im DL-Modus (Display Long) angezeigt. | |
| Falls sich der Benutzer nur für einen bestimmten Teil der Sätze einer PAM-Datei interessiert (z.B. die ersten 80 Bytes eines jeden PAM-Blockes), so kann dies mit dem Kommando AD (Arrange Data) erreicht werden | |
| Anzeige der PAM-Keys | |
| PK | NPK | PAM-Keys/No PAM-Keys. |
| Bei PAM-Dateien / bei der Anzeige von SAM-/ISAM-Dateien im PAM-Format werden anstelle der Datenblöcke die 16 Byte langen PAM-Keys angezeigt. | |
| Auf die PAM-Keys sind alle Display-Kommandos, wie z.B. HEX/HEXO/M/NM/S/W anwendbar. | |
| Standard: NPK | |
| Spaltenzähler einblenden | |
| SC [datei | 'text'] |
| SC | In der oberen Bildschirmhälfte wird ein "Lineal" mit einem Spaltenzähler angezeigt. Das Lineal ist im Display-Modus und bei der Anzeige der Dateienliste aktiv. |
| SC datei | Das Lineal besteht aus dem ersten Satz der angegebenen Datei. Bei Anzeige der Dateienliste wird das Lineal in der Standardform, d.h. ohne Satzinhalt dargestellt. |
| SC 'text' | Das Lineal besteht aus dem in Hochkommas angegebenen Text. |
| SCO | NSC | Das eingeblendete Lineal wird ausgeschaltet. Anstelle von SCO kann auch NSC angegeben werden. Standard: SCO. |
| OL | NOL | Alternativ zu SC/SCO können auch die Kommandos OL/NOL (Orientation Line/No Orientation Line) angegeben werden. |
| Hinweise: | |
| Beim Display von ISAM-Dateien werden die Stellen des ISAM-Schlüssels im Lineal je nach Bildschirmtyp hell oder unterstrichen dargestellt. | |
| Scale ist nützlich als Orientierungshilfe für das Suche-Kommando (Angabe eines Spaltenbereichs). Das Auffinden bestimmter Spalten innerhalb der Datensätze wird durch Scale ebenfalls erleichtert. | |
| Single Record-Modus (Sharupd=Yes) im CFS-Display/Editor | |
| SR | NSR [SHARUPD=YES] |
| Single Record Modus / No Single Record Modus. | |
| SR | Der Single Record-Modus bezieht sich ausschließlich auf den Display/Modify-Modus von CFS und hat zwei verschiedene Wirkungen: |
| a) | Es wird jeweils nur ein Satz bzw. Datenblock am Bildschirm angezeigt. | |
| b) | Bei ISAM- und PAM-Dateien wird in den Sharupd-Modus gewechselt. | |
| Der SR-Modus garantiert die Integrität der Daten auch bei konkurrierendem Zugriff durch verschiedene Benutzer. | |
| NSR | Durch das Kommando NSR wird der Single Record-Modus ausgeschaltet. Eine im Display befindliche ISAM-Datei wird mit SHARUPD=NO eröffnet. |
| NSR SHARUPD=YES Der Zusatz SHARUPD=YES im NSR-Kommando bewirkt, daß die Display-Datei auch im Modus der ganzseitigen Anzeige mit SHARUPD=YES eröffnet ist. |
| Standard: NSR. ISAM-Dateien werden mit SHARUPD=NO angezeigt und modifiziert. | |
| Hinweise: | |
| Der SR-Modus gilt nur für die aktuelle Display-Datei und muß bei einer neuen Datei gegebenenfalls wieder gesetzt werden. | |
| Durch die Kommandofolge SR;KDO bzw. NSR SHARUPD=YES;KDO kann SHARUPD= YES als Standard für alle folgenden Display-Operationen festgesetzt werden. Für weitere Informationen zum Kommando KDO siehe Seite 8-. | |
| Der SR-Modus ist auch beim Display von Banddateien nützlich. Es entfällt damit das Rückspulen des Bandes vor jeder Maskenausgabe. | |
| Suchen von Zeichenfolgen (einfaches Suchargument) | |
| S [-] [n] ,[col] [r] item [, R] [, NC] [, SR] |
| Vom ersten im Sichtfenster angezeigten Satz bis Dateiende/Dateianfang wird nach der angegebenen Zeichenfolge gesucht. Das Sichtfenster wird auf den Satz positioniert, der den ersten Treffer gebracht hat. Im Kommandofeld wird ein Suche-Kommando zum Auffinden des nächsten Treffers vorgegeben. | |
| Durch Drücken der ENTER-Taste (Absenden des Eingabevorschlags) wird die Suche fortgesetzt. | |
| - | Rückwärtssuche: Die Suche erfolgt vom ersten im Sichtfenster angezeigten Datensatz in Richtung Dateianfang. | |
| Standard: Suche in Richtung Dateiende. | ||
| n | Anzahl der Sätze, in denen nach dem Suchargument gesucht wird. | |
| Standard: unbegrenzt viele Sätze. | ||
| col | Spaltenbereich in dem die gesuchte Zeichenfolge beginnen muß. | |
| :col1-col2: | |
| Das erste Zeichen der gesuchten Zeichenfolge muß im Spaltenbereich zwischen col1 und col2 beginnen. | |
| :col1: | |
| Die Zeichenfolge wird nur an der Spalte col1 gesucht und muß dort beginnen. | |
| >:col1: | <:col1: | |
| Die Zeichenfolge wird im Bereich ab Spalte col1 bis Satzende (>:col1:) bzw. vom Satzanfang bis Spalte col1 gesucht (<:col1:). | |
| Standard: Suche in gesamten Spaltenbereich (von Spalte 1 bis Satzende). | ||
| r | > | < | - | |
| > | Suche nach einer Zeichenfolge > item | ||
| < | Suche nach einer Zeichenfolge < item | ||
| - | Suche nach einer Zeichenfolge ungleich item | ||
| Standard: Suche nach einer Zeichenfolge = item. | ||
| item | Suchzeichenfolge: C'string' | L'string' | X'string' | A'string' | |
| C'string' kann zu 'string' abgekürzt werden. In vielen Fällen können sogar die Hochkommas weggelassen werden, siehe Hinweise. | ||
| Enthält string Hochkommas ('), so müssen diese verdoppelt werden (''). | ||
| Die maximale Länge von string beträgt 128 Bytes. | ||
| L'string': Kleinbuchstaben in string werden nicht in Großbuchstaben umgesetzt. | ||
| A'string': Bei der Suche werden Klein- und Großbuchstaben gleich behandelt. | ||
| Beispiel: Der Suchbegriff A'CFS' wird als Treffer erkannt, falls im Datensatz die Zeichenfolge 'CFS' oder 'cfs' oder eine beliebige Kombination aus Groß- und Kleinbuchstaben enthalten ist. | ||
| Über das Kommando SET SEARCHMODE=A kann der A-Modus voreingestellt werden. S,'string' wirkt dann wie S,A'string'. Die Rückkehr in den Standardmodus erfolgt durch SET SEARCHMODE=C. | ||
| Das Suche-Kommando bietet auch die Möglichkeit, mehrere Suchargumente mit Und-, Oder- bzw. Wildcard-Syntax zu verbinden. Die Syntax ist eine Aneinanderreihung einfacher Suchargumente und wird im nächsten Abschnitt "Suchen von Zeichenfolgen (mehrere Suchargumente)" ausführlich beschrieben. | |
| R | Reverse. Die Suche innerhalb der Datensätze erfolgt nicht von links nach rechts, sondern in umgekehrter Reihenfolge von rechts nach links. In diesem Modus können keine Und-, Oder-, Wildcard-Verknüpfungen von mehreren Suchbegriffen angegeben werden. | |
| SR | Single Record. Dieser Indikator ist nur von Bedeutung bei einer Negativ-Suche, d.h. bei der Suche nach einer Zeichenfolge ungleich einem Wert (z.B. S,-X'00'). | |
| Standardmäßig wird bei einer Negativ-Suche ohne Spaltenbereich ein Satz nur dann als Treffer angesehen, falls der Suchstring im gesamten Satz nicht vorkommt. | ||
| Im SR-Modus wird das erste Nicht-Vorkommen des Strings im Satz als Treffer gewertet. Bei der Angabe der Option R (siehe oben) wird automatisch der SR-Modus eingeschaltet. | ||
| S [-] | Suche vom ersten angezeigten Satz bis Dateiende/Dateianfang nach dem zuletzt definierten Suchargument. |
| S? | S?,%name |
| Das zuletzt definierte Suchargument/das mit SP %name in einem Parameter-Set gespeicherte Suchargument wird angezeigt. Beschreibung von SP %name siehe Seite 8-. | |
| Hinweise: | |
| Bei der Angabe des Spaltenbereichs col in der Suchanweisung sind einige Unterschiede zur Spaltenbereichsangabe im EDT zu beachten: | |
| 1) | :col1-col2: besagt, daß der in Hochkommas eingeschlossene Suchbegriff in dem angegebenen Spaltenbereich beginnen muß. | |
| Im EDT muß der Suchbegriff vollständig im angegebenen Spaltenbereich enthalten sein. | ||
| 2) | :col: besagt, daß der in Hochkommas eingeschlossene Suchbegriff genau in der angegebenen Spalte beginnen muß. | |
| Im EDT bewirkt die Angabe einer einzigen Spalte :col:, daß der Suchbegriff von Spalte :col: bis Satzende gesucht wird. In CFS wird dies durch die Angabe >:col2: erreicht, wobei col2=col-1 ist. Durch <:col: kann in CFS eine Zeichenfolge im Bereich vom Satzanfang bis zur Spalte col gesucht werden. | ||
| 'string' kann in den meisten Fällen auch ohne Hochkommas angegeben werden (S,string). Die Hochkommas dürfen lediglich in den Fällen nicht weggelassen werden, in denen string Leerzeichen enthält bzw. von einem Ersatzstring (Seite 8-) oder Write-Kommando (Seite 8-) gefolgt wird. | ||
| Das einmal definierte Suchargument gilt für alle folgenden S-Kommandos und braucht im folgenden nicht mehr angegeben zu werden. Dies gilt solange, bis eine neue Zeichenfolge als Suchbegriff verwendet wird. | ||
| Ist der Benutzer nur an der Anzahl der Treffer in der Datei interessiert, so kann er dies folgendermaßen erreichen: Suche-Kommando S,'string'='',A angeben (nur im Non-Modify-Modus). In diesem Fall wird nur die Anzahl der gefundenen Treffer bis Dateiende gezählt. | |
| Während der Ausführung eines langdauernden Suche-Kommandos kann durch Anwendung der K2-Taste (Verzweigen in die BS2000 Kommando-Ebene) und anschließendes /INTR R die begonnene Suche abgebrochen werden. Das Sichtfenster wird in diesem Fall auf die zuletzt gelesene Stelle in der Datei positioniert. | |
| PAM: Suchen über Blockgrenzen | |
| Bei PAM-Dateien mit BLKSIZE=(STD,1) muß der zu suchende String nicht vollständig in einem Datenblock enthalten sein. Falls der Suchbegriff (z.B. 'DATABASE') am Ende eines PAM-Blocks beginnt und sich am Anfang des nächsten PAM-Blocks fortsetzt (z.B. 'DA' + 'TABASE'), so wird diese Konstellation von CFS ebenfalls als Treffer erkannt. | |
| Beispiele: | |
S,C'XYZ'
| |
| Suche ab dem ersten im Display angezeigten Satz bis zum Dateiende die Zeichenfolge C'XYZ'. | |
S,C'C'' '''
| |
| Suche nach der Zeichenfolge C'_' in der gesamten Datei (Hochkommas in dem zu suchenden String müssen verdoppelt werden). | |
S,L'Datei'
| |
| Suche alle Datensätze, die die Zeichenfolge 'Datei' enthalten. Die im String enthaltenen Kleinbuchstaben werden vor der Suche nicht umgesetzt. | |
S,A'datei'
| |
| Suche alle Datensätze, die die Zeichenfolge 'datei' enthalten. Bei der Suche ist die Groß-/Kleinschreibung der Zeichenfolge im Datensatz unerheblich. | |
S,:73:-' '
| |
| Suche in Spalte 73 eines jeden Satzes nach einem Zeichen ungleich Blank. Sätze mit weniger als 73 Stellen werden hier nicht als Treffer erkannt. | |
S,:1:>X'0054'
| |
| Zur Ermittlung von Datensätzen einer bestimmten Länge kann mit dem Offset-Kommando O-4 das Satzlängenfeld in das Display miteinbezogen werden. Durch das angegebene Suche-Kommando werden in einer RECFORM=V Datei alle Datensätze gefunden, deren Länge inclusive Satzlängenfeld größer als 84 Bytes ist. | |
S,'CFS'=''
| |
| Im Non-Modify-Modus: Es wird die Anzahl der Datensätze gezählt, in denen der Suchbegriff 'CFS' mindestens einmal vorkommt. Im Non-Modify-Modus wird keine Ersetzung des Suchstrings in der Datei vorgenommen. | |
S,'CFS'='',A
| |
| Im Non-Modify-Modus: Es wird die Gesamtanzahl der Treffer gezählt. | |
| A: mehrfache Treffer in einem Datensatz werden entsprechend oft gezählt. | |
| Im Modify-Modus würde der Suchstring in ISAM-Dateien bei jedem Vorkommen innerhalb eines Satzes gelöscht. | |
S,''
| |
| Gibt in der Hinweiszeile die Länge des ersten im Sichtfenster angezeigten Satzes aus (sucht nach dem Satzende). | |
| Suchen (Vergleichen von Spaltenbereichen) | |
| S [-] [n] ,:col1-col2: r :col3: |
| Vom ersten im Sichtfenster angezeigten Satz bis Dateiende/Dateianfang wird der Inhalt des mit :col1-col2: angegebenen Spaltenbereichs mit dem Inhalt des bei :col3: beginnenden Spaltenbereichs verglichen. Das Sichtfenster wird auf den ersten Satz positioniert, bei dem die beiden Spaltenbereiche im Inhalt übereinstimmen. Im Kommandofeld wird ein Suche-Kommando zum Auffinden des nächsten Treffers vorgegeben. Durch Drücken der ENTER-Taste (Absenden des Eingabevorschlags) wird die Suche fortgesetzt. | |
| - | Rückwärtssuche: Die Suche erfolgt vom ersten im Sichtfenster angezeigten Datensatz in Richtung Dateianfang. | |
| Standard: Suche in Richtung Dateiende. | ||
| n | Anzahl der Sätze, in denen gesucht werden soll. | |
| Standard: unbegrenzt viele Sätze. | ||
| col1 | Anfangsspalte des ersten Bereichs. | |
| col2 | Endespalte des ersten Bereichs. | |
| r | = | > | < | - | |
| = | die Spaltenbereiche müssen im Inhalt übereinstimmen. | |
| > | der Inhalt des ersten Spaltenbereichs muß größer als der Inhalt des zweiten Spaltenbereichs sein. | |
| < | der Inhalt des ersten Spaltenbereichs muß kleiner als der Inhalt des zweiten Spaltenbereichs sein. | |
| -= | der Inhalt des ersten Spaltenbereichs muß ungleich dem Inhalt des zweiten Spaltenbereichs sein. | |
| Standard: = | ||
| Hinweise: | |
| Beide Spaltenbereiche müssen vollständig im Satz enthalten sein. Falls einer der Bereiche über das Satzende hinausgeht, wird von CFS Ungleichheit signalisiert. | |
| Das Vergleichen von Spaltenbereichen kann wie das Suchen von Zeichenfolgen mit den Operatoren "+" und "," mit weiteren Suchbedingungen verknüpft werden. Näheres hierzu im Abschnitt "Suchen von Zeichenfolgen (mehrere Suchargumente)". | |
| Beispiele: | |
S,:1-20:=:101:
| |
| Es wird der Inhalt der ersten 20 Bytes jedes Satzes mit dem Inhalt der Spalte 101 bis 120 verglichen. Bei Gleichheit wird ein Treffer signalisiert. | |
S,:1-1:>:12:
| |
| Es wird der Inhalt der ersten Spalte jedes Satzes mit dem Inhalt der Spalte 12 verglichen. Falls der Inhalt von Spalte 1 größer als der Inhalt von Spalte 12 ist, wird ein Treffer signalisiert. | |
| Suchen von Zeichenfolgen (mehrere Suchargumente) |
| S [-] [n] , such [ vk such ] [...] ..... [, A] [, NC] | Format 1 | |
| S ... , ( ) [, A] [, NC] | Format 2 | |
| S ... , %name | %? [, A] [, NC] | Format 3 | |
| S ... , ( s-dat ) [, A] [, NC] | Format 4 | |
| Vom ersten im Sichtfenster angezeigten Satz bis Dateiende/Dateianfang wird nach der Kombination der angegebenen mehrfachen Suchargumente gesucht. | |
| Die Syntax für die einzelnen Suchargumente such ist im Abschnitt "Suchen von Zeichenfolgen (einfaches Suchargument)" beschrieben. | |
| Jedes Suchargument wird durch einen Operator vk mit dem jeweils nächsten Suchargument verknüpft. Die Anzahl der zu verknüpfenden Suchargumente ist beliebig. | |
| In der obigen und in den folgenden Syntaxbeschreibungen steht S [-] [n] für den Bereich, über den sich die Suche erstrecken soll: Rückwärtssuche, Anzahl der Sätze, in denen gesucht werden soll. Ausführliche Beschreibung Seite 8-. | |
| Im folgenden werden die 4 Formate der Mehrfachsuche beschrieben. | |
| Mehrfachsuche - Format 1 | |
| S [-] [n] , such [ vk such ] [...] ..... [, A] |
| such | [col] [r] item | |
| einfaches Suchargument wie im vorhergehenden Abschnitt "Suchen von Zeichenfolgen (einfaches Suchargument)" ausführlich beschrieben. | ||
| vk | , | + | * | |
| Verknüpfungsoperator mit dem vorausgegangenen einfachen Suchargument such. | ||
| , | Suche im aktuellen Satz das vorausgegangene oder das nachfolgende Suchargument. Die Suchbedingung gilt als erfüllt, wenn zumindest eines der beiden Such-Items im Datensatz enthalten ist. | ||
| + | Suche im aktuellen Satz das vorausgegangene und das nachfolgende Suchargument. Die Suchbedingung ist erfüllt, wenn beide Suchargumente im Datensatz enthalten sind. Die Reihenfolge der Suchargumente im Datensatz ist ohne Bedeutung. | ||
| *[n] | Suche im aktuellen Satz das vorausgegangene und das nachfolgende Suchargument. Die Suchbedingung ist erfüllt, wenn beide Suchargumente im Datensatz enthalten sind. Die Suchargumente müssen in der gleichen Reihenfolge auftreten, wie im Suche-Kommando angegeben. | ||
| n | Anzahl der Trennzeichen mit beliebigem Inhalt, die im Datensatz zwischen dem ersten und zweiten Suchargument enthalten sein müssen. Falls n nicht angegeben wurde, so ist jede beliebige Anzahl von Trennzeichen, einschließlich 0 möglich. | ||
| Es können beliebig viele Konstrukte der Art vk such aneinandergereiht werden. | |
| Bei Verknüpfung durch die Und-Bedingung '+' können auch geklammerte Ausdrücke angegeben werden: (.. , .. , ...)+(.. , .. , ...). Ein Beispiel hierzu ist weiter unten (Seite 8-) beschrieben. | |
| A | All: Bei einer Suche, die mehrere mit "oder" (",") verknüpfte Suchargumente enthält, wird die Suche nicht nach dem ersten im Datensatz gefundenen Item abgebrochen. Dies hat längere Ausführungszeiten beim Suchvorgang zur Folge. Dafür werden jedoch alle Treffer-Items mit den entsprechenden Spaltenangaben in der Hinweiszeile der CFS-Maske angezeigt. | |
| Standard: Die Suche wird nach dem ersten gefundenen Item beendet. | ||
| NC | No Columns. Im DL-Modus (Display Long) wird die Spaltenpositionierung auf den jeweiligen Treffer unterdrückt (gleiches Verhalten wie im DS-Modus). | |
| Hinweise: | |
| Die Reihe der Suchargumente und Verknüpfungsoperatoren wird linear abgearbeitet. Falls mehrere mit "+" bzw. "*" verknüpfte Suchargumente angegeben wurden und eines von ihnen nicht im Datensatz enthalten ist, so wird der Suchvorgang beendet bzw. beim nächsten, mit oder "," verknüpften Such-Item fortgesetzt. | |
| Für jedes einzelne Suchargument such kann ein Spaltenbereich (:col1-col2: / :col: / >:col: / <:col:), eine Negativ-Bedingung ( -'item' ), sowie ein Such-Item in Normaldarstellung ( 'item' ), in hexadezimaler Darstellung ( X'item' ) oder ein Such-Item in Groß-/Kleinschreibung ( L'item' ) angegeben werden. Bei einem Such-Item in Normaldarstellung können die Hochkommas in der Regel sogar weggelassen werden. Durch S,FLAG*STATEMENT werden z.B. alle Datensätze gesucht, die die Zeichenfolge 'FLAG' und irgendwo danach die Zeichenfolge 'STATEMENT' enthalten. Weitere Informationen siehe Syntaxbeschreibung und Hinweise auf Seite 8-. | |
| In der Kommandozeile von CFS stehen insgesamt 71 Bytes zur Aufnahme des gesamten Mehrfachsuche-Kommandos zur Verfügung. Dies wird sich bei der Angabe einer größeren Anzahl von Suchargumenten oft als Engpaß erweisen. Um dieser Situation zu begegnen, kann über das Kommandofeld von CFS eine spezielle Such-Maske angefordert werden. Zur Anforderung der Suchmaske dient das im folgenden beschriebene Format 2 des Suche-Kommandos: S,( ). | |
| Beispiele: | |
S,'='*'(','DC '*'('*')'
| |
| Es werden alle Datensätze gesucht, die eine der beiden Bedingungen erfüllen: | |
| - | Zeichen '=' und irgendwann danach Zeichen '('. z.B. '=A(...)', '=V(...)' | |
| - | Zeichenfolge 'DC ' und irgendwo danach die Zeichen '(' und ')'. | |
| z.B. 'DC A(...)', 'DC Y(...)' | ||
S,:1:>X'004C'+:1:<X'0054'
| |
| Zur Ermittlung von Datensätzen einer bestimmten Länge kann mit dem Offset-Kommando O-4 das Satzlängenfeld in das Display miteinbezogen werden. Durch das angegebene Suche-Kommando werden in einer RECFORM=V Datei alle Datensätze gefunden, deren Länge größer als 76 Bytes und kleiner als 84 Bytes ist. | |
S,-L'a'+-L'b'+-L'c'
| |
| Es werden alle Sätze gesucht, die keinen der Kleinbuchstaben a, b oder c enthalten. | |
S,L'a',>L'a'+<L'z',L'z'
| |
| Es werden alle Sätze gesucht, die mindestens einen Kleinbuchstaben enthalten. | |
S,'A'+'D1','B'+'D1','A'+'D2','B'+'D2'
| |
| Mehrfachsuche - Format 2 | |
| S [-] [n] , ( ) [, A] |
| Durch () wird eine spezielle Such-Maske angefordert. Es stehen dem Benutzer damit 18 Bildschirmzeilen zur Eingabe umfangreicher Suchargumente zur Verfügung. Der Zusatz A hat die gleiche Bedeutung wie im Format 1 des Suche-Kommandos. | |
| Die Zeilen 4 bis 21 der Suche-Maske dienen zur Aufnahme der Suchargumente. Diese sind lückenlos, d.h. ohne zusätzliche Blanks einzugeben. | |
| Durch Betätigung der ENTER-Taste wird der Suchvorgang gestartet. Die K1-Taste bewirkt den Abbruch der Definition des Sucharguments. Mit der F3-Taste kann die ausgefüllte Suche-Maske in einer Hardcopy-Datei festgehalten werden. | |
| Im Kommandofeld können BS2000-Kommandos, sowie das SP-Kommando eingegeben werden. | |
| SP %name [,jrsave] |
| Save Parameters. Mit diesem Kommando wird die in der Suche-Maske eingetragene Suchbedingung unter dem angegebenen Namen in der Datei CFS.JRSAVE [.jobname] bzw. in einer mit /FILE datei,LINK=JRSAVE zugewiesenen Datei gesichert, sofern im SP-Kommando der Zusatz jrsave nicht angegeben wurde. Die genaue Regel, nach der der Name der JRSAVE-Datei gebildet wird, ist auf Seite 27- unter CFS.JRSAVE beschrieben. | |
| %name | ein- bis 44-stelliger alphanumerischer Schlüsselbegriff für den abzuspeichernden Parameter-Set. | |
| jrsave | Name der JRSAVE-Datei. Der Name sollte nur dann angegeben werden, wenn die Parameter in eine andere als die von CFS standardmäßig verwendete JRSAVE-Datei (siehe oben) gesichert werden. | |
| Ein Beispiel für das Ausfüllen der Suche-Maske und für die Anwendung des Kommandos SP %name finden Sie im nächsten Abschnitt "Suchen mit Ersetzen". | |
| Der Benutzer kann auf ein mit SP gesichertes Suchargument zurückgreifen durch das Kommando S,%name (siehe unten), bzw. S?,%name (Seite 8-). | |
| Mehrfachsuche - Format 3 | |
| S [-] [n] , %name | %? [, jrsave] [, A] |
| Es werden alle Datensätze gesucht, die eine komplexe Suchbedingung erfüllen, die in der Suche-Maske mit dem Kommando SP %name in einem Parameter-Set gesichert wurde (siehe Seite 8-). Der optionale Zusatz A hat die gleiche Bedeutung wie beim oben beschriebenen Format 1 des Suche-Kommandos. | |
| %? | Es werden alle in Frage kommenden Parametersets in einer Maske angezeigt. Durch Markieren mit 'x' kann einer der vorgeschlagenen Parametersets ausgewählt werden. Durch Markieren mit 'm' wird der Inhalt des Parametersets angezeigt und kann noch modifiziert werden. | |
| Mehrfachsuche - Format 4 | |
| S [-] [n] , ( s-dat | bibl ( [t/] elem) ) [, A] |
| s-dat | bibl ( [t/] elem ) | |
| Name der Datei bzw. des Bibliothekselements, in dem die Suchitems gespeichert sind. Falls bei einem Bibliothekselement der Elementtyp nicht angegeben ist, wird S/ ergänzt, sofern es sich um eine PLAM-Bibliothek handelt. | ||
| Mit der Suche-Maske (siehe Seite 8-) können mehrfache Suchargumente mit maximal 15*80 Zeichen angegeben werden. Diese Beschränkung gilt nicht für die Suche-Datei s-dat. Für diese Datei besteht keine Einschränkung bezüglich der Größe und der Anzahl der Suchargumente. | ||
| Format der Datei s-dat: | ||
| Jeder Datensatz in s-dat beschreibt eine Suchbedingung, die mit der im nächsten Datensatz enthaltenen Suchbedingung verknüpft wird. Falls am Ende des Datensatzes keines der Verknüpfungszeichen ,/+/* angegeben wurde, so wird standardmäßig die Oder-Bedingung als Verknüpfung mit dem Suchbegriff im nächsten Datensatz angenommen. Innerhalb eines Datensatzes können mehrere Suchitems mit dem Oder-, Und-, Wildcard-Zeichen verknüpft werden. Die maximale Länge von 250 Bytes sollte jedoch in keinem Datensatz überschritten werden. | ||
| A | Dieser optionale Zusatz hat die gleiche Bedeutung wie beim oben beschriebenen Format 1 des Suche-Kommandos. | |
| Beispiel: | |
S,(NAMEN)
| |
| Es werden in der aktuellen Display-Datei alle Datensätze gesucht, die mindestens einen der in der Datei NAMEN aufgeführten Suchbegriffe enthalten. Ein Suchbegriff wird durch einen Satz in der unten stehenden Datei festgelegt. | |
| Die Datei NAMEN habe folgenden Inhalt: | |
|
'ALBERT' 'ANDREAS' 'AMADEUS'+'THEODOR'+'ERNST' ........ 'CARL'*'PHILIP'*'EMANUEL' |
| Und-Verknüpfung ( + ): Ein Satz mit dem String 'AMADEUS' wird nur dann als Treffer gewertet, wenn im gleichen Satz auch die Strings 'THEODOR' und 'ERNST' enthalten sind. Die Reihenfolge der einzelnen Items ist bei der Suche mit dem Verknüpfungszeichen '+' ohne Bedeutung. Ein Satz mit 'ERNST THEODOR AMADEUS' würde z.B. die Bedingung erfüllen. | |
| Wildcard-Verknüpfung ( * ): Ein Satz mit dem String 'CARL' wird nur dann als Treffer gewertet, wenn im gleichen Satz an späterer Stelle die Strings 'PHILIP' und 'EMANUEL' enthalten sind. | |
| Es ist möglich, die Suche jedes einzelnen Strings auf einen bestimmten Spaltenbereich zu begrenzen. | |
| Im oben aufgeführten Beispiel könnten die Hochkommas vor und nach den Suchstrings weggelassen werden, da die gesuchten Zeichenfolgen keine Blanks oder andere Sonderzeichen enthalten. | |
| Suchbegriffe, die Kleinbuchstaben enthalten, können in der Form L'...' angegeben werden. In diesem Fall wird die zwischen den Hochkommas stehende Zeichenfolge nicht in Großbuchstaben umgewandelt. | |
| Für eine Beschreibung der Syntax und der verschiedenen Abkürzungsmöglichkeiten siehe Seite 8-. | |
| Suchen mit Ersetzen | |
| S [-] [n], ...= [len] item2 [, ...= [len] item2 ] .... [, opt] |
| S.... steht für ein einfaches Suchargument wie im Abschnitt "Suchen von Zeichenfolgen (einfaches Suchargument)" beschrieben. | |
| len | wahlweise Längenangabe. Beim Ersetzungsvorgang wird item2 solange wiederholt, bis die angegebene Länge len erreicht ist. Falls nicht angegeben: len = Länge des Ersetzungsstrings. | |
| item2 | Ersetzungsstring: C'...' | L'...' | X'...' | |
| Über das Kommando SET REPLACEMODE=F|L kann bestimmt werden, welcher Suchstring bei einer Verknüpfung S,'src1'*'src2'='str3' durch str3 ersetzt wird: Standardmäßig der erste (src1) oder der letzte (src2). | |
| Das Konstrukt: ...= [len] item2 kann beliebig oft wiederholt werden. Als Trennzeichen sind Kommas zu verwenden (Oder-Bedingungen). | ||
| Falls die Kommandozeile von CFS hierfür nicht ausreicht, kann durch S,()[,opt] eine eigene Suchmaske angefordert werden. Auch die Formate 3 und 4 des Suche-Kommandos können für das Suchen mit Ersetzen benützt werden: | ||
| S, %name [, opt] | S, ( s-dat ) [, opt]. | ||
| Die Optionen [,opt] können auch in der Suchmaske/in der Datei s-dat im Anschluß an das letzte Paar suchstring=ersatzstring angegeben werden. | ||
| opt | C | R | A | Q | |
| wahlweise Zusatzoptionen zur Steuerung des Ersetzungsvorgangs. | ||
| C | Die C-Option (Change) bewirkt einen echten Austausch von Suche- und Ersetzungsstring in den Datensätzen. Die Satzlängen werden in diesem Fall entsprechend angepaßt. Die Option C bewirkt eine Ersetzung analog der des EDT. | |
| Standardmäßig (ohne C-Option) erfolgt die Ersetzung in der Weise, daß der gefundene Suchstring durch den angegebenen Ersatzstring überschrieben wird. Die Länge des modifizierten Datensatzes ändert sich auch dann nicht, wenn Suchstring und Ersetzungsstring verschiedene Länge haben. | ||
| Die C-Option ist nur bei ISAM-Dateien bzw. bei in ISAM-Dateien umgesetzten SAM-Dateien anwendbar. RECFORM=V ist ebenfalls Voraussetzung für die C-Option. | |
| R | Reverse. Der Suche- und Ersetzungsvorgang innerhalb der Datensätze erfolgt in umgekehrter Reihenfolge von rechts nach links. In diesem Modus können keine mehrfachen Suche- und Ersetzungsstrings angegeben werden. | |
| In Kombination mit der R-Option kann nur die C-Option (siehe oben) angegeben werden: CR. | ||
| Standard: Die Ersetzung erfolgt von links nach rechts. | |
| A | Alle Treffer innerhalb eines Datensatzes werden ersetzt (analog der EDT-Anweisung: @ON...CA'...'T'...'). | |
| Standard: Die Ersetzung wird nur beim ersten Treffer in einem Datensatz durchgeführt. | |
| Falls weder die C-, noch die A-Option angegeben wurde, so wird der erste Treffer eines jeden Datensatzes durch den angegebenen Ersetzungsstring überschrieben. | |
| Q | Query: Vor jedem Ersetzungsvorgang wird der Benutzer um Bestätigung gebeten. Das Sichtfenster wird 20 Spalten links vom Trefferstring positioniert. Durch Betätigung der ENTER-Taste wird der Trefferstring durch den Ersatzstring ausgetauscht. Durch Betätigung der K3-Taste wird der Ersetzungsvorgang nicht ausgeführt. In beiden Fällen (ENTER/K3) wird nach Betätigung der Datenübertragungstaste auf den nächsten Treffer positioniert. Durch Überschreiben des im Kommandofeld vorgegebenen S-Kommandos mit Blank wird die Suche abgebrochen. | |
| Standard: kein Query-Modus. Die Trefferstrings werden ohne Benutzeranfrage durch die Ersatzstrings ausgetauscht. | ||
| Hinweise: | |
| Die C-, A-, und Q-Option können auch kombiniert werden: CA / CQ / AQ / CAQ. Die Reihenfolge der Kombination ist hierbei nicht frei wählbar. Zuerst muß die C-Option angegeben werden falls gewünscht, danach die A-Option und als letztes die Q-Option. CA entspricht dem Change All des EDT. CAQ ist eine Variante, die vor jeder Ersetzung eine Bestätigung durch den Benutzer verlangt. | |
| Bei Anwendung der Option CAQ (Change All Query) und bei unterschiedlicher Länge des Such- und Ersetzungsstrings kann der Fall eintreten, daß am Ende des aktuellen Treffersatzes einige Zeichen nicht dargestellt werden (Satz erscheint abgeschnitten). Dieser Effekt hat keinerlei Auswirkungen auf die tatsächlichen Daten. | |
| Falls beim Suchen mit Ersetzen die C-Option nicht angegeben wurde, so ist folgendes zu beachten: | |
| Ist der Ersatzstring (item2) länger als der Suchstring (item1), so werden Daten, die rechts von item1 stehen, durch item2 überschrieben. | |
| Ist der Ersatzstring (item2) kürzer als der Suchstring (item1), so wird der rechtsstehende Teil von item1 nicht verändert. | |
| ISAM: innerhalb des Schlüssels wird item1 nicht gesucht und es findet demzufolge auch keine Ersetzung statt. | |
| PAM: Suchen über Blockgrenzen | |
| Bei PAM-Dateien muß der zu suchende String nicht vollständig in einem Datenblock enthalten sein. Falls der Suchbegriff (z.B. 'DATABASE') am Ende eines PAM-Blocks beginnt und sich am Anfang des nächsten PAM-Blocks fortsetzt (z.B. 'DA' + 'TABASE'), so wird diese Konstellation von CFS ebenfalls als Treffer erkannt und durch den Ersatzstring ausgetauscht. | |
| Beispiele: | |
S,C'C''passw'''=C'C''passw-neu''',CAQ
| |
| Im ISAM-Modus wird nach der Zeichenfolge C'passw' gesucht. Bei jedem Treffer wird der Benutzer gefragt, ob der String durch C'passw-neu' ersetzt werden soll. ENTER-Taste: Ersetzung vornehmen und weitersuchen. K3-Taste: Keine Ersetzung und weitersuchen. Durch das Austauschen der Strings findet eine Verschiebung der rechtsstehenden Daten statt. | |
S,:9:''=60X'FF'
| |
| Vom ersten angezeigten Satz bis Dateiende werden die Daten ab Spalte 9 (Satzanfang = Spalte 1) in der Länge 60 auf X'FF' gesetzt (überschrieben). | |
S,:90:X'FF'+:1990:X'FA00'+:1545:''=5X'FF'
| |
| Vom ersten angezeigten Satz bis Dateiende werden alle Sätze gesucht, die sowohl in Spalte 90 X'FF' als auch in Spalte 1990 die Zeichenfolge X'FA00' enthalten. Bei allen, diese Bedingung erfüllenden Datensätzen werden die Spalten 1545 bis 1549 mit X'FF' überschrieben. | |
S,'ABCD'='',CA
| |
| Vom ersten angezeigten Satz bis Dateiende wird die Zeichenfolge ABCD im gesamten Spaltenbereich gesucht und aus dem Satz entfernt. Das Entfernen der Zeichenfolge kann in einem Satz an mehreren Stellen erfolgen (Option A). Die Verarbeitungsoption C hat zur Folge, daß die resultierenden Sätze in ihrer Länge verkürzt werden. | |
S,()
| |
| Aufgrund dieses Kommandos wird die Suche-Maske ausgegeben, in die der Benutzer folgende Such- und Ersetzungsanweisung einträgt: | |
} dd.mm.yy hh:mm:ss HOST: ........ TSN: .... {
| |
| Vom ersten angezeigten Satz bis Dateiende werden alle Kleinbuchstaben (siehe Parameter A am Ende) in die entsprechenden Großbuchstaben umgewandelt. Durch das Kommando SP %CAP wird die Suche- und Ersetzungsanweisung unter dem Namen %CAP in der Datei CFS.JRSAVE [.jobname] bzw. in einer mit /FILE datei, LINK=JRSAVE zugewiesenen Datei gespeichert. Die genaue Regel, nach der der Name der JRSAVE-Datei gebildet wird, ist auf Seite 27- ("von CFS angelegte Dateien/Jobvariablen") beschrieben. | |
S,%CAP
| |
| Die unter dem Namen %CAP gespeicherte Suche- bzw. Ersetzungsanweisung wird zur Ausführung gebracht. | |
S?,%CAP
| |
| Die unter dem Namen %CAP gespeicherte Suche- bzw. Ersetzungsanweisung wird am Bildschirm angezeigt (Maske siehe oben) und kann danach zur Ausführung gebracht werden. | |
| Suchen mit Löschen der gefundenen Sätze/Strings | |
| S ...=E [ I | P | PI | S | SI ] [, Q] [, R] |
| S ... steht für eine einfache oder zusammengesetzte Suchanweisung wie in den vorhergehenden Abschnitten "Suchen von Zeichenfolgen (einfaches Suchargument / mehrere Suchargumente)" beschrieben. | |
| Wird die Zeichenfolge in einem Datensatz gefunden, so werden folgende Löschoperationen ausgeführt: | |
| E | Löschen des gesamten Datensatzes. | |
| EI [,A] | Löschen des gefundenen Suchitems. Der Datensatz wird entsprechend verkürzt. | |
| EI,A: Es werden alle Trefferitems im Satz gelöscht. In diesem Fall darf die Option ,R (Reverse) nicht angegeben werden. | ||
| Standard: Es wird das erste gefundene Suchitem im Satz gelöscht. | ||
| EP | Löschen vom Ende des ISAM-Schlüssels bis zum Beginn des Suchitems (Prefix). | |
| EPI | Löschen vom Ende des ISAM-Schlüssels bis zum Ende des Suchitems (Prefix + Item). | |
| ES | Löschen vom Ende des Suchitems bis zum Ende des Satzes (Suffix). | |
| ESI | Löschen vom Anfang des Suchitems bis zum Ende des Satzes (Suffix + Item). | |
| Q | Query: Der Benutzer wird bei jedem die Suchbedingung erfüllenden Treffer gefragt, ob die Löschoperation durchgeführt werden soll. Durch Betätigung der ENTER-Taste wird die vorgeschlagene Löschoperation bestätigt und zum nächsten Treffersatz positioniert. Durch Betätigung der K3-Taste wird die Löschoperation nicht ausgeführt und der nächste Treffer angeboten. Durch Überschreiben des im Kommandofeld stehenden S-Kommandos wird die Suche abgebrochen. | |
| Standard: kein Query-Modus. Das Löschen wird ohne Benutzeranfrage ausgeführt. | ||
| R | Reverse. Der Suche- und Ersetzungsvorgang innerhalb der Datensätze erfolgt in umgekehrter Reihenfolge von rechts nach links. In diesem Modus können keine mehrfachen Suche- und Ersetzungsstrings angegeben werden. | |
| Standard: Die Ersetzung erfolgt von links nach rechts. | |
| Hinweis: | |
| Die oben beschriebenen Varianten des Suche-Kommandos sind nur im Modify-Modus und nur für ISAM-Dateien zulässig. SAM-Dateien müssen zuvor mit dem Kommando IS[AM] in das ISAM-Format umgewandelt werden. | |
| Beispiele: | |
S,:1:>'0100'+:1:<'0500'=E
| |
| Vorausgesetzt wird eine ISAM-Datei mit Recform=V,Keypos=5,Keylen=8. Vom ersten angezeigten Satz an werden alle Sätze mit ISAM-Schlüsseln größer als 0100 und kleiner als 0500 gelöscht. | |
S,:10-12:'1',:10-12:'2',:10-12:'3'=E,Q
| |
| Dem Benutzer wird jeder Datensatz, der in den Spalten 10 bis 12 die Zeichen 1, 2 oder 3 enthält zum Löschen angeboten (Query-Modus, Parameter Q). Durch Betätigung der ENTER-Taste wird der angezeigte Satz gelöscht und der nächste Treffersatz aufgesucht. Durch Betätigung der K3-Taste wird der angezeigte Satz nicht gelöscht und der nächste Treffersatz aufgesucht. | |
| Suchen mit direkter Ausgabe der gefundenen Sätze am Bildschirm | |
| S ... steht für eine einfache oder zusammengesetzte Suchanweisung wie in den vorhergehenden Abschnitten "Suchen von Zeichenfolgen (einfaches Suchargument / mehrere Suchargumente)" beschrieben. | |
| Bei Dateien mit FCBTYPE=SAM und PAM wird dem Satzinhalt die entsprechende Satz- bzw. Blocknummer vorangestellt. Nach Ausgabe von maximal 21 Sätzen wird eine Überlaufkontrolle eingefügt ("Please acknowledge / End: K1"). Durch Betätigung der K1-Taste wird der Suchvorgang beendet. Jede andere Eingabe bewirkt eine Fortsetzung der Suche bis zum Dateiende bzw. bis zum Erreichen der im Suche-Kommando angegebenen maximalen Satzanzahl (Snn,'...'=P). | |
| Nach Beendigung des Suchvorgangs wird der Display-Bildschirm wieder auf den gleichen Satzausschnitt positioniert wie vor Beginn des Suche-Kommandos. | |
| Standardmäßig wird pro Treffersatz am Bildschirm nur eine Zeile (80 Byte) ausgegeben. Befindet sich das Suchitem nicht in den ersten 80 Bytes des Satzes, so wird ein Ausschnitt des Treffersatzes angezeigt, der 40 Bytes zur linken und rechten Seite des Suchitems darstellt. | |
| PL | Print Long. Die Treffersätze werden bis zu einer maximalen Länge von 2048 Bytes am Bildschirm dargestellt. | |
| Hinweis: | |
| Nach Beendigung der Anzeige der Treffer ist die Suchbedingung noch gespeichert. Durch Eingabe des Kommandos S kann das Sichtfenster zum ersten Satz positioniert werden, der das Suchitem enthält. | |
| Beispiele: | |
S,'MVC'*'BLANK'=P
| |
| Sucht vom ersten, im Sichtfenster angezeigten Satz bis Dateiende nach Sätzen, die die Zeichenfolge 'MVC' und rechts davon 'BLANK' enthalten. Die gefundenen Sätze werden im Line-Modus am Bildschirm ausgegeben. Nach Beendigung des Suchvorgangs wird das Sichtfenster auf den Satz positioniert, bei dem das Suche-Kommando aufgesetzt wurde. | |
S100,:100-200:X'47'=PL
| |
| Sucht in den nächsten 100 Sätzen/Datenblöcken jeweils im Spaltenbereich 100 - 200 nach der Zeichenfolge X'47'. Die gefundenen Sätze werden in der vollen Länge am Bildschirm ausgegeben. | |
| Suchen mit Wegschreiben der Treffer | |
| S ....=W [ datei | LINK=WFCB [,C] [,E|O] [,Q] [,BLK] [, f-attr|?] [ /[:col:] [ len] [, NS] ] ] |
| S ... steht für eine einfache oder zusammengesetzte Suchanweisung wie in den vorhergehenden Abschnitten "Suchen von Zeichenfolgen (einfaches Suchargument / mehrere Suchargumente)" beschrieben. | |
| datei | Die Treffersätze werden in die angegebene Datei oder falls kein Dateiname wurde, in die zuletzt eröffnete Write-Datei geschrieben. | |
| LINK=WFCB | Die Treffersätze werden in die mit /FILE ...,LINK=WFCB,... zugewiesene Datei geschrieben. | |
| C | Die Ausgabedatei wird nach dem letzten geschriebenen Satz geschlossen. | |
| E | Die Ausgabedatei wird mit Open=Extend eröffnet. | |
| O | Eine bestehende Ausgabedatei wird überschrieben (Open=Output). | |
| Standard: siehe Hinweise. | ||
| Q | Query: Der Benutzer wird bei jedem die Suchbedingung erfüllenden Satz gefragt, ob dieser Satz in die Write-Datei geschrieben werden soll. Durch Betätigung der ENTER-Taste wird der Satz weggeschrieben und zum nächsten Treffersatz positioniert. Durch Betätigung der K3-Taste wird der Satz nicht weggeschrieben und der nächste Treffer angeboten. Durch Überschreiben des im Kommandofeld stehenden S-Kommandos wird die Suche abgebrochen. | |
| Standard: kein Query-Modus. Die Treffersätze werden ohne Benutzeranfrage in die Write-Datei geschrieben. | ||
| Die E/O und die Q-Option können, durch ein Komma getrennt, auch kombiniert angegeben werden. | |
| BLK | Write Block: Diese Option ist nur von Bedeutung, falls die aktuelle Display-Datei eine PAM-Datei ist und der Pamkey-Modus eingeschaltet ist (Kommando PK). Aufgrund der Option BLK werden die zu den Pam-Keys gehörigen Blöcke in die Write-Datei übertragen. Standard: Im Pamkey-Modus werden nur die Pam-Keys in eine SAM-Datei geschrieben. | |
| f-attr | Dateiattribute der Write-Datei entsprechend der Syntax eines FILE- oder ADD-FILE-LINK Kommandos. | |
| Beispiel (Parameter gemäß FILE-Kommando): | ||
FCBTYPE=SAM,RECFORM=F,RECSIZE=80,BLKSIZE=(STD,16),SPACE=(120,30),VOLUME=PVT001,DEVICE=D3480
| ||
| Beispiel (Parameter gemäß ADD-FILE-LINK Kommando): | ||
ACCESS=*SAM,REC-F=*FIX,REC-S=80,BUFFER-L=*STD(16)
| ||
| ? | Es wird der SDF-Fragebogen des Kommandos /ADD-FILE-LINK (ADFL) ausgegeben. | |
| Die vorgegebenen Werte der ersten beiden Parameter (LINK-NAME=WFCB und FILE-NAME=...) dürfen nicht verändert oder gelöscht werden. | ||
| Standard: Für die Ausgabedatei werden alle Dateiattribute der Display-Datei außer LOGLEN, VALLEN, VALPROP, DSPACE übernommen. | ||
| Falls f-attr angegeben, so werden nur diese Attribute für die Ausgabedatei verwendet. Es werden keine Attribute der Display-Datei in die Ausgabedatei übernommen. f-attr kann nicht zusammen mit LINK=WFCB (s.o.) angegeben werden. | ||
| col | Es wird nur der Teil der Treffersätze ab Spalte :col: weggeschrieben (:1: bezeichnet den Satzanfang). Standard: Es wird ab Satzanfang weggeschrieben ( :1: ). | |
| len | Es wird ab der angegebenen Spalte/ab Satzanfang in der Länge len weggeschrieben. Standard: Es wird in der maximalen Länge (bis zum Satzende) geschrieben. | |
| NS | No Skip. Datensätze, bei denen die Spalte :col: außerhalb des beschriebenen Bereichs liegt, werden bei der Ausgabe in die Write-Datei nicht unterdrückt. Es wird ein Datensatz mit der Länge 4 erzeugt. Sätze dieser Art enthalten ein Satzlängenfeld, jedoch keine Daten. | |
| Standard: Datensätze, bei denen die Spalte :col: außerhalb des beschriebenen Bereichs liegt, werden bei der Ausgabe in die Write-Datei unterdrückt. | ||
| Hinweise: | |
| Bei ISAM-Dateien können im DUPKEY-Modus (Kommando DUPK) Sätze mit gleichen Schlüsseln in die Write-Datei übertragen werden. Bei ausgeschaltetem DUPKEY-Modus (Standard) wird bei mehreren Sätzen mit gleichen Schlüsseln nur der jeweils letzte in der Write-Datei gespeichert. Falls die Speicherung des jeweils ersten Datensatzes mit gleichen Schlüsseln gewünscht ist, so ist dazu die Suche vom Dateiende in Richtung Dateianfang auszuführen: S-,...=W... | |
| Für die Write-Datei ist der DUPKEY-Modus wirksam, der zum Zeitpunkt des Eröffnens der Write-Datei (erstes W- / S..=W-Kommando) bestand. Ein nachträgliches Umschalten des DUPKEY-Modus hat auf die Write-Datei keine Wirkung, es sei denn, der Display-Modus wird vorübergehend beendet (Drücken der K1-Taste) und danach wieder aufgenommen. | |
| Falls hinter dem Namen der Write-Datei keine der Optionen E/O (Extend/ Overwrite) angegeben wurde, so gilt folgende Regelung: | |
| Falls die Write-Datei im aktuellen CFS-Lauf zum ersten Mal angesprochen wird, so wird als Open-Modus in jedem Fall O (Overwrite) angenommen, d.h. die Datei wird neu angelegt bzw. überschrieben. | |
| Falls in mehreren W / S...=W-Kommandos nacheinander die gleiche Write-Datei angegeben wurde, so wird sie standardmäßig mit Open=Extend eröffnet. | |
| Durch die E-/O-Option kann vom Benutzer ein vom Standardfall abweichender Open-Modus angegeben werden. | |
| Beispiele: | |
S,:1:>X'0054'=W CFS.REC80
| |
| Zur Ermittlung der Datensätze mit einer bestimmten Länge kann mit dem Kommando O-4 das Satzlängenfeld in das Display miteinbezogen werden. Durch das angegebene Suche-Kommando (Syntax siehe Seite 8-) werden in einer RECFORM=V Datei alle Datensätze gefunden, deren Datenbereich eine Länge von mehr als 80 Bytes aufweist. Die gefundenen Sätze werden in die Datei CFS.REC80 kopiert. | |
S,L'a',>L'a'+<L'z',L'z'=W CFS.KLEIN
| |
| Es werden alle Datensätze, die Kleinbuchstaben enthalten, in die Datei CFS.KLEIN geschrieben. Syntax siehe Seite 8-. | |
S,'ABC'=W SAVE.ABC,FCBTYPE=SAM/:9:100
| |
| Vom ersten angezeigten Satz bis Dateiende wird in der Display-Datei der String 'ABC' gesucht. Jeder Satz, in dem mindestens ein Treffer gefunden wurde, wird ab Spalte 9 in der Länge 100 in die Ausgabedatei SAVE.ABC geschrieben. Die Datei SAVE.ABC soll unabhängig vom Format der im Display angezeigten Datei mit FCBTYPE=SAM angelegt werden. Standardmäßig, d.h. falls keine Dateiparameter angegeben wurden, erhält die Write-Datei die gleichen Datei- und Satzformate wie die Display-Datei. | |
| Suchen mit Wegschreiben in eine CFS-Prozedurvariable | |
| S ....=W, (&var) [ /[:col:] [ len] ] |
| Der Datensatz der Display-Datei, der beim Suchvorgang einen Treffer gebracht hat, wird vollständig oder als Teil in die CFS-Prozedurvariable mit dem angegebenen Namen übertragen. | |
| :col: | Es wird nur der Teil des Displaysatzes ab Spalte :col: in die Prozedurvariable übertragen (:1: bezeichnet den Satzanfang). | |
| Standard: Es wird der vollständige Datensatz übertragen. | ||
| len | Es wird ab der angegebenen Spalte/ab Satzanfang in der in len angegebenen Länge geschrieben. | |
| Standard: Es wird in der vollen Länge, d.h. bis zum Satzende weggeschrieben. Die Maximallänge ist jedoch in jedem Fall auf 80 Bytes begrenzt. | ||
| Hinweise: | |
| Falls mehrere Datensätze im Verlauf der Suche als Treffer gemeldet werden, so wird der jeweils letzte in die CFS-Prozedurvariable übertragen. Bei der Suche vom Dateiende zum Dateianfang (S-) wird der erste, in der Datei enthaltene Treffer, in die Prozedurvariable geschrieben. | |
| Bei ISAM-Dateien können im DUPKEY-Modus (Kommando DUPK) Sätze mit gleichen ISAM-Schlüsseln in die Write-Datei übertragen werden. | |
| Bei ausgeschaltetem DUPKEY-Modus (NDUPK, Standard) wird bei mehreren Sätzen mit gleichen Schlüsseln nur der jeweils letzte in der Write-Datei gespeichert. | |
| Wegschreiben von Sätzen aus Display-Datei | |
| W[n][, datei | LINK=WFCB [, C|E|O|BLK] ] [, f-attr|?] [ /[:col:] [ len] [, NS] ] [, SC] |
| Vom ersten im Sichtfenster angezeigten Satz ausgehend werden n Sätze in die angegebene Write-Datei weggeschrieben. Das Sichtfenster wird um diese n Sätze weiter positioniert. | |
| n | Anzahl der in die Write-Datei zu übertragenden Sätze. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für alle Sätze. | ||
| Standard: n = 1. | ||
| datei | Name der Datei, in die die Sätze zu schreiben sind (Write-Datei). | |
| Falls weggelassen: Es wird in die zuletzt angegebene Write-Datei geschrieben. | ||
| LINK=WFCB | Die Datensätze werden in die mit /FILE ...,LINK=WFCB,... zugewiesene Datei geschrieben. | |
| C | Die Ausgabedatei wird nach dem letzten geschriebenen Satz geschlossen. | |
| E | Die Ausgabedatei wird mit Open=Extend eröffnet. | |
| O | Eine bestehende Ausgabedatei wird überschrieben (Open=Output). | |
| BLK | Diese Option ist nur von Bedeutung, falls die aktuelle Display-Datei eine PAM-Datei ist und der Pamkey-Modus eingeschaltet ist (Kommando PK). Durch die Option BLK werden die zu den Pam-Keys gehörigen Blöcke in die Write-Datei übertragen. Standard: Es werden nur die Pam-Keys in die Datei geschrieben. | |
| f-attr | Dateiattribute der Write-Datei entsprechend der Syntax eines FILE- oder ADD-FILE-LINK Kommandos. | |
| Beispiel (Parameter gemäß FILE-Kommando): | ||
FCBTYPE=SAM,RECFORM=F,RECSIZE=80,BLKSIZE=(STD,16),SPACE=(120,30),VOLUME=PVT001,DEVICE=D3480
| ||
| Beispiel (Parameter gemäß ADD-FILE-LINK Kommando): | ||
ACCESS=*SAM,REC-F=*FIX,REC-S=80,BUFFER-L=*STD(16)
| ||
| ? | Es wird der SDF-Fragebogen des Kommandos /ADD-FILE-LINK (ADFL) ausgegeben. | |
| Die vorgegebenen Werte der ersten beiden Parameter (LINK-NAME=WFCB und FILE-NAME=...) dürfen nicht verändert oder gelöscht werden. | ||
| Standard: Für die Ausgabedatei werden alle Dateiattribute der Display-Datei außer LOGLEN, VALLEN, VALPROP, DSPACE übernommen. | ||
| Falls f-attr angegeben, so werden nur diese Attribute für die Ausgabedatei verwendet. Es werden keine Attribute der Display-Datei in die Ausgabedatei übernommen. f-attr kann nicht zusammen mit LINK=WFCB (siehe oben) angegeben werden. | ||
| :col: | Es wird nur der Teil der Displaysätze ab Spalte :col: weggeschrieben | |
| (:1: = Satzanfang). | ||
| Standard: Es werden die vollständigen Datensätze übertragen ( :1: ). | |
| len | Es wird ab der angegebenen Spalte/ab Satzanfang in der in len angegebenen Länge geschrieben. | |
| Standard: Es wird in der vollen Länge, d.h. bis zum Satzende weggeschrieben. | ||
| NS | No Skip. Datensätze, bei denen die Spalte :col: außerhalb des beschriebenen Bereichs liegt, werden bei der Ausgabe in die Write-Datei nicht unterdrückt. Es wird ein Datensatz mit der Länge 4 erzeugt. Sätze dieser Art enthalten ein Satzlängenfeld, jedoch keine Daten. | |
| Standard: Datensätze, bei denen die Spalte :col: außerhalb des beschriebenen Bereichs liegt, werden bei der Ausgabe in die Write-Datei unterdrückt. | ||
| SC | Ist im Display ein Zeilenlineal eingeblendet (Scale), so wird der Inhalt dieses Zeilenlineals als erster Satz in die Write-Datei geschrieben. | |
| Standard: Das Zeilenlineal wird nicht in die Ausgabedatei aufgenommen. | ||
| Hinweise: | |
| Die Write-Datei wird beim Verlassen des Display-Modus über die K1-Taste bzw. Kommando LST automatisch geschlossen. Bei einem nachfolgenden W-Kommando ohne Angabe eines Dateinamens ( W [n] ) wird die zuletzt benutzte Write-Datei im EXTEND-Modus (SAM-Datei) bzw. im INOUT-Modus (ISAM-/PAM-Datei) eröffnet. | |
| Wurde hinter dem Namen der Write-Datei keine der Optionen E/O (Extend/ Overwrite) angegeben, so gilt folgende Regelung: | |
| Falls die Write-Datei im aktuellen CFS-Lauf zum ersten Mal angesprochen wird, so wird als Open-Modus in jedem Fall O (Overwrite) angenommen, d.h. die Datei wird neu angelegt bzw. überschrieben. | |
| Falls in mehreren W / S...=W-Kommandos nacheinander die gleiche Write-Datei angegeben wurde, so wird sie standardmäßig mit Open=Extend eröffnet. | |
| Durch die E-/O-Option kann vom Benutzer ein vom Standardfall abweichender Open-Modus angegeben werden. | |
| Bei ISAM-Dateien können im DUPKEY-Modus (Kommando DUPK) Sätze mit gleichen ISAM-Schlüsseln in die Write-Datei übertragen werden. | |
| Bei ausgeschaltetem DUPKEY-Modus (NDUPK, Standard) wird bei mehreren Sätzen mit gleichen Schlüsseln nur der jeweils letzte in der Write-Datei gespeichert. | |
| Für die Write-Datei ist der DUPKEY-Modus wirksam, der zum Zeitpunkt des Eröffnens der Write-Datei (erstes Write-Kommando) bestand. Ein nachträgliches Umschalten des DUPKEY-Modus hat auf die Write-Datei keine Wirkung, es sei denn, der Display-Modus wird vorübergehend beendet (Drücken der K1-Taste) und danach wieder aufgenommen. | |
| Mit dem Write-Kommando kann eine sequentielle Datei nach einem Schlüsselbegriff aufsteigend sortiert werden: | |
W9999,datei2,FCBTYPE=ISAM,KEYPOS=kk,KEYLEN=ll
| |
| kk und ll bezeichnen den in den Datensätzen der sequentiellen Datei enthaltenen Schlüsselbegriff. Falls mehrere Datensätze mit gleichem Schlüsselbegriff existieren, muß vor Write das Kommando DUPK (siehe oben) eingegeben werden. Die nach dem gewünschten Kriterium sortierte ISAM-Datei kann anschließend wieder in eine sequentielle Datei zurückkonvertiert werden. Die Konvertierung einer SAM-Datei in eine ISAM-Datei mit gleichzeitiger Umsortierung gemäß einem vorgegebenen Schlüsselbegriff kann auch über die Variable Action ONXCONV vorgenommen werden. | |
| Das Write-Kommando ist prinzipiell auch dazu geeignet, mehrere Dateien/Bibliothekselemente in einer Ausgabedatei zusammenzufügen. | |
| Ein einfacheres Mittel hierfür bietet die Variable Action ONXLIST... unter Angabe der NH-Option (No Header). Mehr hierzu auf Seite 5-. | |
| Beispiel: | |
| Die im folgenden aufgeführte CFS-Prozedur sucht in der aktuellen Display-Datei alle Sätze mit einem vorgegebenen String und schreibt n Sätze davor und m Sätze danach in die Datei &W-FILE. | |
|
*PROC N,(&ITEM,&W-FILE,&M,&N) SR *&ANZ=&M+&N *&ANZ=&ANZ+1 S,&ITEM *IF &CFSMSG(1,20) -= '>> SYNTACTICAL ERROR' SKIP .LOOP *WRITESYS '&CFSMSG' *SKIP .ENDE2 .LOOP *IF &CFSMSG(53,3) = 'NOT' SKIP .ENDE -&M W&ANZ,&W-FILE S *SKIP .LOOP .ENDE *K1 .ENDE2 | |
| Wegschreiben eines Display-Satzes in eine CFS-Prozedurvariable | |
| W,(&var) [ /[:col:] [ len] ] [ ,L] [ ,KP] |
| Der erste im Sichtfenster angezeigte Datensatz der Display-Datei wird vollständig oder als Teil in die CFS-Prozedurvariable mit dem angegebenen Namen übertragen. | |
| :col: | Es wird nur der Teil des Displaysatzes ab Spalte :col: in die Prozedurvariable übertragen (:1: = Satzanfang). | |
| Standard: Es wird der vollständige Datensätze übertragen. | ||
| len | Es wird ab der angegebenen Spalte/ab Satzanfang in der in len angegebenen Länge geschrieben. | |
| Standard: Es wird in der vollen Länge, d.h. bis zum Satzende weggeschrieben. Die maximale Länge ist jedoch auf 80 Bytes begrenzt. | ||
| L | Long. Ist der Datensatz länger als 80 Bytes, so wird für die ersten 80 Bytes zusätzlich eine Variable &var-P0 erzeugt. Für die 2-ten 80 Bytes wird eine Prozedurvariable mit dem Namen &var-P1 generiert, in die die entsprechenden Daten übertragen werden. Dies geht rekursiv bis zur vollen Länge der zu übertragenden Daten (&var-Pn) | |
| KP | Keep Position. Bei Pam-Dateien wird nach dem Schreiben der Variablen wieder der gleiche Block angezeigt und nicht wie sonst, auf den nächsten Block weitergeblättert. Zusammen mit dem Kommando SR (Single Record) bewirkt dies eine Reduzierung der IOs. | |
| Editieren von ISAM-Dateien beliebigen Formats | |
| Im Modify-Modus können ISAM-Dateien mit erweiterten und zum Teil EDT-ähnlichen Funktionen bearbeitet werden. Datensätze können z.B. kopiert, gelöscht, zusammengefügt und in ihrer Position innerhalb der Datei verschoben werden. Auch das Einfügen und Löschen von Spaltenbereichen, sowie das Aufsplitten von Sätzen wird unterstützt. | |
| Sätze kopieren/löschen/zusammenfügen/verschieben | |
| * | Kopierpuffer zurücksetzen. Durch diese Markierung in der ersten Stelle eines ISAM-Schlüssels wird der Kopierpuffer zurückgesetzt (gelöscht), ohne daß ein Kopiervorgang vorgenommen wurde. |
| A | B | Kopierpuffer nach/vor einem Datensatz einfügen. Erste Stelle des ISAM-Schlüssels mit dem Zeichen B (Before) oder A (After) überschreiben. Die restlichen Stellen des Schlüssels dürfen nicht verändert werden. Es können aus dem Kopierpuffer nur soviele Sätze eingefügt werden, wie die Differenz der Schlüssel vor und nach der Einfügeposition zuläßt. Z.B können zwischen zwei Sätzen mit den Schlüsseln 00011100 und 00011200 maximal 99 Sätze eingefügt werden. Wurden die Sätze mit der Markierung M (Move) in den Kopierpuffer eingetragen, so wird für jeden eingefügten Satz der entsprechende Originalsatz gelöscht. |
| I[n][,len] | Einfügen von Leersätzen. Vor dem markierten Satz werden n, aus Blanks bestehende Leersätze eingefügt. Die einstellige Anzahl n muß direkt nach dem Markierungszeichen I angegeben werden. Falls kein Wert für n angegeben wurde, werden 9 Sätze eingefügt. Die optionale Angabe len spezifiziert die Länge der einzufügenden Sätze ohne ISAM-Schlüssel. len muß durch ein Blank vom restlichen Teil des ISAM-Schlüssels getrennt werden. |
| Falls kein Wert für len angegeben ist, wird als Standardwert len=72 verwendet. | |
| J | Zusammenfügen von Sätzen. Erste Stelle des ISAM-Schlüssels mit dem Zeichen J (Join) überschreiben. Der so markierte Satz wird an das Ende des vorhergehenden Satzes angehängt. Der ISAM-Schlüssel des mit J gekennzeichneten Satzes wird dabei ausgeblendet. Bei der Markierung mehrerer aufeinanderfolgender Sätze mit J werden diese gemeinsam an den vorhergehenden Satz angefügt. |
| E | Sätze löschen. Erste Stelle des ISAM-Schlüssels mit E (Eliminate) überschreiben. |
| C | Direktes Kopieren von Sätzen über ISAM-Schlüssel. Erste Stelle des ISAM-Schlüssels mit dem Zeichen C (Copy) überschreiben und an den restlichen Stellen die Position, an der der neue Satz eingefügt werden soll, eintragen. Für die Position des zu kopierenden Satzes wird die erste Stelle des ISAM-Schlüssels unverändert aus dem Ursprungssatz übernommen. Die Daten des zu kopierenden Satzes dürfen nicht zugleich mit dem Schlüssel verändert werden. |
| Direktes Verschieben von Sätzen über ISAM-Schlüssel. Werden ISAM-Schlüssel modifiziert, so verschieben sich die Datensätze in ihrer Position innerhalb der Datei entsprechend (Move). | |
| Hinweise: | |
| Der Kopierpuffer von CFS wird mit dem Verlassen des Display-Modus nicht automatisch gelöscht. Es ist daher möglich, mit den Markierungen C/R Datensätze aus einer Datei in eine/mehrere andere Dateien zu übertragen. | |
| Werden die Daten im Hexadezimalmodus angezeigt, so sind anstelle der oben beschriebenen Markierungszeichen C/A/B/... die entsprechenden Hexadezimalwerte (X'C3'/X'C1'/X'C2') an der ersten Stelle der ISAM-Schlüssel einzutragen. Es besteht jedoch auch die Möglichkeit, die Markierungszeichen wie gewohnt im Character-Format einzugeben. Dazu ist das Zeichen im ersten Halbbyte des Schlüssels und ein Leerzeichen im zweiten Halbbyte des Schlüssels einzugeben. | |
| Datensätze, deren ISAM-Schlüssel an der ersten Stelle bereits eines der Zeichen C/A/B/... aufweisen, können in der oben beschriebenen Weise nicht bearbeitet werden. Für diese Sonderfälle ist das Kommando RD anzuwenden (siehe unten). | |
| Weder im DUPK noch im NDUPK-Modus ist es möglich, aus einer Folge von Datensätzen mit gleichen ISAM-Schlüsseln gezielt den zweiten, dritten Satz, usw. mit Move/Copy/Eliminate zu bearbeiten. Bei Sätzen mit gleichen ISAM-Schlüsseln wird in jedem Fall der erste Satz mit diesem Schlüssel der entsprechenden Operation unterworfen. | |
| Zeichen für Satzmarkierung redefinieren | |
| RD keyword=x | ReDefine. |
| Mit dem Kommando RD können die Markierungssymbole zur Bearbeitung von ISAM-Schlüsseln geändert werden. | |
| keyword | AFTER | BEFORE | CLEAR | COPY | ELIM | INSERT | JOIN | MOVE | RETAIN | |
| Die Schlüsselwörter bestimmen das zu ändernde Markierungssymbol. | ||
| x | neuer Wert des Markierungssymbols. Es kann jedes über die Tastatur eingebbare Zeichen gewählt werden. Standardmäßig sind folgende Werte definiert: AFTER=A, BEFORE=B, CLEAR=*, COPY=C, ELIM=E, JOIN=J, INSERT=I, MOVE=M, RETAIN=R. | |
| Die Anzeige der aktuellen Markierungssymbole und deren Änderung ist auch über die SET-Maske (Kommando SET) möglich. | |
| Beispiel: | |
RD ELIM=D
| |
| Durch das obige Kommando wird das Zeichen zum Löschen von Sätzen von 'E' in 'D' (=Delete) geändert. | |
| Delete Characters (Spalten löschen) | |
| DEL [n], [:col:] [ len|char] |
| Beginnend mit dem ersten angezeigten Satz wird in n Sätzen der angegebene Spaltenbereich gelöscht. Die Länge der Sätze verkürzt sich entsprechend. | |
| n | Satzanzahl: 1 <= n <= 99999. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für alle Sätze. | ||
| Standard: n =1. Es wird nur im ersten angezeigten Satz gelöscht. | ||
| :col: | 1 <= col <= 32000 | col = $ (Satzende). | |
| erste zu löschende Spalte. Bei DEL..,:$:len werden vom jeweiligen Satzende nach links die Zeichen in der angegebenen Länge gelöscht. | ||
| Standard: Es wird der Bereich unmittelbar rechts vom ISAM-Schlüssel gelöscht (bei Dateien mit KEYPOS=5 und KEYLEN=8 ist dies die Spalte :9: ). | ||
| len | Länge des zu löschenden Spaltenbereichs ab der angegebenen Anfangs-Spalte col bzw. vom Satzende nach links (:$:). | |
| Standard: len = 1. | ||
| char | C'x'|X'xx'. Das angegebene Zeichen wird in jedem Satz von rechts nach links bis zum ersten Auftreten eines anderen Zeichens gelöscht. Falls das Zeichen n mal angegeben wird, so werden die letzten n-1 Zeichen am Satzende nicht gelöscht. | |
| Diese Angabe ist nur sinnvoll in Verbindung mit der Spaltenangabe :$:. | ||
| Beispiele: | |
DEL 9999,:500:10
| |
| Vom ersten angezeigten Satz an werden in 9999 Sätzen (bzw. bis Dateiende) ab der Spalte 500 10 Zeichen gelöscht. | |
DEL$,:$:10
| |
| In allen Sätzen der Datei werden die letzten 10 Stellen gelöscht. | |
DEL$,:$:C' '
| |
| In den Sätzen der Datei werden Blanks am Satzende gelöscht. | |
DEL$,:$:C' '
| |
| In den Sätzen der Datei werden alle Blanks am Satzende bis auf eines gelöscht. | |
| Sätze löschen | |
| ER [n] | Eliminate Records. Beginnend mit dem zweiten am Bildschirm angezeigten Satz werden n Sätze gelöscht. |
| n | Anzahl der zu löschenden Datensätze. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für alle Sätze. | ||
| Standard: n = 1. | ||
| ER key1-key2 | Beginnend mit key1 werden alle Sätze mit Schlüsseln kleiner oder gleich bis key2 gelöscht. Die Schlüssel können in einer der folgenden Darstellungsweisen angegeben werden: string | [C] 'string' | X'string'. Die Schlüssel key1 und key2 müssen nicht vollständig, d.h. in der ganzen Länge, angegeben werden. Es genügt, den eindeutigen Anfang des gewünschten Anfangs- und Endeschlüssels zu spezifizieren. key1 wird in diesem Fall rechts mit Low Value (X'00') und key2 mit High Value (X'FF') aufgefüllt. |
| Beispiele: | |
ER
| |
| Der zweite am Bildschirm angezeigte Satz wird gelöscht. | |
ER 999
| |
| Beginnend mit dem zweiten am Bildschirm angezeigten Satz werden 999 folgende Sätze gelöscht. | |
ER 0003-01
| |
| Es werden alle Datensätze gelöscht, deren Schlüssel im Bereich zwischen '0003*' und '01*' liegen. * steht hier für eine Zeichenfolge beliebigen Inhalts, die sich bis zum Ende des Schlüssels erstreckt. | |
ER X'AF'-X'AF'
| |
| Es werden alle Datensätze gelöscht, deren Schlüssel mit X'AF' beginnen. | |
| Leersätze einfügen | |
| IL [n[+|-]], [len] [item] |
| Insert blank Lines. Zwischen dem ersten und dem zweiten angezeigten Satz werden n Leersätze eingefügt. | |
| n | Anzahl der einzufügenden Sätze. Standard: n = 1. | |
| Die Schrittweite der eingefügten ISAM-Schlüssel berechnet sich aus der Differenz zwischen dem zweiten und dem ersten angezeigten Schlüssel dividiert durch die Anzahl n. | ||
| n+ | Die Sätze werden mit der kleinstmöglichen Schrittweite beginnend vom unteren Schlüssel an eingefügt. | |
| n- | Die Sätze werden mit der kleinstmöglichen Schrittweite unterhalb des oberen Schlüssels eingefügt. | |
| len | Länge des Datenteils der einzufügenden Sätze. Der ISAM-Schlüssel und das Satzlängenfeld zählen bei der Länge des Datenteils nicht mit. | |
| Standard: 72. Es werden Sätze mit 72 Datenbytes eingefügt. | ||
| item | Zeichenfolge mit der die einzufügenden Sätze aufgefüllt werden sollen. | |
| [C]'string' | L'string' | X'string' | ||
| Standard: C'_'. Die einzufügenden Sätze enthalten Spaces. | ||
| Beispiele: | |
IL 100,256C'0123456789'
| |
| Zwischen dem ersten und zweiten angezeigten Satz werden 100 Sätze eingefügt, soweit es die Differenz der Schlüssel erlaubt. Die Länge der Sätze ergibt sich aus Länge des ISAM-Schlüssels + 4 Byte Satzlängenfeld + 256 Byte Daten. Die Daten der eingefügten Sätze werden auf 256 Stellen mit dem Muster C'0123456789' aufgefüllt. Der angegebene String wird im Ausgabesatz 25-mal voll und einmal in den ersten 6 Byte aneinandergereiht. | |
IL ,80
| |
| Nach dem ersten angezeigten Satz wird ein Satz mit 80 Blanks eingefügt. | |
| Insert Characters (Spalten einfügen) | |
| INS [n], [:col:] [len] [item] |
| Beginnend mit dem ersten im Sichtfenster angezeigten Satz wird in n Sätzen an der Spalte :col: in der Länge len die Zeichenfolge item eingefügt. Die Datensätze verlängern sich entsprechend. | |
| n | Satzanzahl: 1 <= n <= 99999. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für alle Sätze. | ||
| Standard: n = 1. Insert wird nur im ersten angezeigten Satz durchgeführt. | ||
| :col: | 1 <= col <= 32000 | col = $ (Satzende). | |
| Spalte, nach der eingefügt werden soll. Aufgrund von INS..., :$: ... erfolgt die Einfügung jeweils am Ende des Datensatzes. | ||
| Standard: Die Einfügung erfolgt unmittelbar nach dem ISAM-Schlüssel. Bei Dateien mit KEYPOS=5 und KEYLEN=8 ist dies die Spalte :9: | ||
| len | Länge der Einfügung. Standard: len = Länge des Items bzw. len = 1, falls item nicht angegeben wurde. | |
| item | Einzufügende Zeichenfolge: C'string' | X'string'. C'string' kann auch als 'string' angegeben werden. Falls die Länge von item kleiner ist als die angegebene Einfügelänge len, so wird item solange wiederholt, bis die in len angegebene Länge erreicht ist. Ist die Länge von item größer als len, so werden nur die ersten Stellen von item zur Einfügung benutzt. | |
| Standard: C'_', d.h. anstelle eines vorgegebenen Items werden Blanks eingefügt. | ||
| Beispiele: | |
INS 9999,:500:10X'FF'
| |
| Vom ersten angezeigten Satz an wird in 9999 Sätzen (bzw. bis Dateiende) ab Spalte 500 die Zeichenfolge X'FFFFFFFFFFFFFFFFFFFF' (=10X'FF') eingefügt. | |
INS :$:'1234567890'
| |
| Im ersten angezeigten Satz wird am Satzende die Zeichenfolge C'1234567890' angefügt. | |
INS :20:10
| |
| Im ersten angezeigten Satz werden ab der Spalte 20 10 Spaces eingefügt. | |
| Sätze aus zweiter Datei einfügen | |
| IR [n[+|-]] [, datei] [, params] |
| Es werden n Sätze aus der angegebenen Referenzdatei in die aktuelle Display-Datei kopiert. | |
| n | Anzahl der zu kopierenden Sätze. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für alle Sätze. | ||
| Standard: n = 1. | ||
| Die Schrittweite der eingefügten ISAM-Schlüssel berechnet sich aus der Differenz zwischen dem zweiten und dem ersten angezeigten Schlüssel dividiert durch die Anzahl n. | ||
| n+ | Die Sätze werden mit der kleinstmöglichen Schrittweite beginnend vom unteren Schlüssel an eingefügt. | |
| n- | Die Sätze werden mit der kleinstmöglichen Schrittweite unterhalb des oberen Schlüssels eingefügt. | |
| datei | Referenzdatei, aus der die Sätze kopiert werden. Die Referenzdatei kann vom Fcbtyp SAM oder ISAM sein. | |
| Standard: Falls datei nicht angegeben wurde, so wird auf die zuletzt eröffnete Referenzdatei zugegriffen. | ||
| params | W | NW | K | KN | NK | B | C | |
| oder eine Kombination dieser Werte getrennt durch Kommas. | ||
| W | Wrap. Nach Erreichen des Endes der Referenzdatei wird der interne Zeiger wieder auf den Dateianfang gesetzt. Auf diese Weise können Datensätze aus der Referenzdatei wiederholt in die Display-Datei eingefügt werden. | |
| NW | No Wrap. Nach Erreichen des Endes der Referenzdatei bleibt der interne Zeiger dort stehen. Es wird kein weiterer Satz in die Display-Datei kopiert. Durch die B-Option (siehe unten) kann der interne Zeiger wieder auf den Beginn der Referenzdatei gesetzt werden. | |
| Standard: NW. | ||
| K | Keys. CFS fügt die Sätze der Referenzdatei entsprechend ihrem Originalschlüssel positionsgerecht in die Display-Datei ein (gestreute Einfügung). | |
| Falls die Referenzdatei vom FCBTYPE=SAM ist, müssen die Daten für die ISAM-Schlüssel in den einzufügenden Sätzen enthalten sein. | ||
| Im K-Modus überschreiben Datensätze aus der Referenzdatei entsprechende Sätze mit den gleichen ISAM-Schlüsseln in der Display-Datei. | ||
| Im K-Modus ist ein zuvor abgesetztes DUPK-Kommando insofern wirksam, als Sätze aus der Referenzdatei mit gleichen ISAM-Schlüsseln wie in der Display-Datei, dort eingefügt werden können (kein Überschreiben). Dadurch ist es möglich, in der Display-Datei Datensätze mit gleichen ISAM-Schlüsseln zu erzeugen. | ||
| KN | Keys No overwrite. Gleiche Funktion wie bei K (siehe oben), jedoch überschreiben Datensätze aus der Referenzdatei nicht Sätze mit den gleichen ISAM-Schlüsseln in der Display-Datei. | |
| NK | No Keys. Die in der Referenzdatei vorhandenen ISAM-Schlüssel werden beim Einfügen nicht mit übernommen. Die Referenzdatei wird wie eine sequentielle Datei behandelt. Die Sätze der Referenzdatei werden zwischen dem ersten und zweiten am Bildschirm angezeigten Satz in die Display-Datei eingefügt. Es werden neue ISAM-Schlüssel von CFS vergeben. | |
| Standard: NK. | ||
| B | Beginning. Die Referenzdatei wird wieder vom Anfang an gelesen. Diese Option sollte bei Ausgabe der Fehlermeldung "EOF on source-file" verwendet werden. | |
| C | Close. Die Referenzdatei wird nach dem Einfügen geschlossen. Standardmäßig bleibt die Referenzdatei solange geöffnet, bis CFS beendet oder ein IR-Kommando mit einer anderen Referenzdatei abgesetzt wird. | |
| Hinweise: | |
| Das IR-Kommando ist das Gegenstück zum W-Kommando bzw. zum Suche-Kommando mit kombiniertem Write (S...=W...). Mit dem Write-Kommando können bestimmte Sätze in eine Ausgabedatei von gleichem Format wie die Display-Datei geschrieben werden. Nach gesonderter Bearbeitung dieser Sätze in der Write-Datei können sie mit dem Kommando IR wieder in die Originaldatei eingespielt werden. | |
| Falls sowohl die Display-, als auch die IR-Datei ISAM-Dateien sind, so müssen KEYPOS und KEYLEN in beiden Dateien übereinstimmen. | |
| Bei Erreichen des Endes der Referenzdatei bleibt der interne Zeiger dort stehen. Durch IR [n],,B wird die Referenzdatei wieder vom Anfang gelesen. | |
| Die Referenzdatei wird mit Verlassen des Display-Modus nicht geschlossen. Ein explizites Schließen der Referenzdatei kann mit der Option C im IR-Kommando (siehe oben) erreicht werden. | |
| Beispiele: | |
IR 9999,CFS.DAT1
| |
| Es werden maximal 9999 Sätze der Datei CFS.DAT1 zwischen dem ersten und zweiten angezeigten Satz in die Display-Datei eingefügt. Es besteht jedoch die Einschränkung, daß nur soviele Datensätze eingefügt werden, wie freie Schlüssel zwischen dem ersten und zweiten Satz existieren. Gegebenenfalls wird der Einfügevorgang mit DUPKEY-Error abgebrochen. | |
IR 20,CFS.DAT2,W
| |
| Angenommen die Referenzdatei CFS.DAT2 enthält nur einen Datensatz, so wird dieser Satz dann 20 mal zwischen dem ersten und zweiten angezeigten Satz der Display-Datei eingefügt. | |
IR 999,CFS.DAT3,K
| |
| Angenommen Display-Datei und Referenzdatei CFS.DAT3 sind ISAM-Dateien mit dem gleichen Dateiformat. Es werden soviele Datensätze wie in der Datei CFS. DAT3 vorhanden, maximal jedoch 999 schlüsselgerecht in die Display-Datei übertragen (K-Option). Falls in der Datei bereits Sätze mit entsprechenden Schlüsseln enthalten sind, so werden diese durch die zu übertragenden Sätze überschrieben (nur falls NDUPK-Modus von CFS eingeschaltet ist). | |
| Split (Sätze trennen) | |
| SPLIT [n[+|-]], :col: [,R] |
| Beginnend mit dem ersten im Sichtfenster angezeigten Satz werden die nächsten n Sätze an der Spalte :col: aufgetrennt. Der rechts von :col: stehende Teil wird in einen Folgesatz übertragen. Für diesen Satz wird ein neuer Schlüssel generiert. | |
| n | Satzanzahl: 1 <= n <= 99999. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für alle Sätze. | ||
| Standard: n = 1. Es wird nur der erste angezeigte Satz getrennt. | ||
| n+ | Die aufgetrennten Sätze werden mit der kleinstmöglichen Schrittweite beginnend vom unteren Schlüssel an eingefügt. | |
| n- | Die aufgetrennten Sätze werden mit der kleinstmöglichen Schrittweite unterhalb des oberen Schlüssels eingefügt. | |
| :col: | 1 <= col <= 32000 | |
| Spalte, nach der der Satz getrennt werden soll. Die Spaltenangabe darf nicht innerhalb des ISAM-Schlüssels liegen. | ||
| R | Repeat. Das SPLIT-Kommando wird für einen Datensatz solange angewendet, bis alle erzeugten Teilsätze eine Länge kleiner als col besitzen. | |
| Beispiele: | |
SPLIT 9999,:88:,R
| |
| Beginnend mit dem ersten angezeigten Satz an werden die nächsten 9999 Sätze in Teilsätze zu jeweils 88 Bytes (inklusive ISAM-Schlüssel) aufgespalten. | |
SPLIT :258:
| |
| der erste angezeigte Satz wird bei Spalte 258 in zwei Sätze aufgeteilt. | |
| Join (Sätze zusammenfügen) | |
| JOIN [n], {J=m | step} |
| n | Anzahl der Sätze, auf die das Kommando JOIN anzuwenden ist: 1 <= n <= 99999. | |
| Das Zeichen '$' anstelle einer Anzahl n steht für ale Sätze. | ||
| Standard: n = 1. Es wird nur ein Satz bearbeitet. | ||
| Das Join-Kommando ist die Umkehrung des Split-Kommandos. Je nach Angabe des Parameters J=m bzw. step erfolgt eine verschiedene Verarbeitung. | |
| J=m | Es werden jeweils m aufeinanderfolgende Sätze zu einem einzigen Satz verbunden. | |
| step | Beginnend mit dem zweiten im Sichtfenster angezeigten Satz werden die nächsten n Sätze in folgender Weise bearbeitet: Liegt der ISAM-Schlüssel des Satzes innerhalb der Step-Size (siehe unten), so wird er an den vorhergehenden Satz angefügt. | |
| step = 0 | 10 | 100 | 1000 | 10000 | ||
| Als Schrittweite muß der Wert angegeben werden, mit dem die ISAM-Schlüssel zwischen den einzelnen Sätzen ursprünglich erhöht wurden. In diesem Zusammenhang siehe auch Kommando IS auf Seite 8-. | ||
| Ein Satz wird an den vorhergehenden Satz angefügt, falls sein ISAM-Schlüssel | ||
| gleich dem Schlüssel des Vorgängersatzes ist | (step=0) | |
| in der letzten Stelle einen Wert > 0 und < 10 enthält | (step=10) | |
| in den letzten 2 Stellen einen Wert > 0 und < 100 enthält | (step=100) | |
| in den letzten 3 Stellen einen Wert > 0 und < 1000 enthält | (step=1000) | |
| in den letzten 4 Stellen einen Wert > 0 und < 10000 enthält | (step=10000). | |
| Liegt ein Satz innerhalb der Step-Size, so ist gewährleistet, daß dies ein durch ein früheres SPLIT-Kommando (siehe oben) erzeugter Folgesatz ist. Die Zuordnung zu dem entsprechenden Hauptsatz ist damit festgelegt. | ||
| Hinweis: | |
| Bei der Bearbeitung einer durch das Kommando SPLIT in kürzere Sätze aufgeteilten ISAM-Datei im EDT oder im CFS-Editor ist zu beachten, daß die ISAM-Schlüssel nicht verändert werden dürfen, daß keine neuen Sätze eingefügt und keine vorhandenen Sätze gelöscht werden dürfen. Nur wenn diese Bedingungen erfüllt sind, ist ein korrektes Zusammenfügen der gesplitteten Sätze durch das Kommando JOIN gewährleistet. | |
| Display und Editieren mit SHARUPD=YES | |
| Bei Display-Dateien mit Fcbtype=ISAM/PAM wird der Open mit SHARUPD=YES nur durchgeführt, falls die Datei im normalen Display-Modus (SHARUPD=NO) wegen eines DVS-Fehlers nicht eröffnet werden konnte. Wird die Datei im normalen Display-Modus bereits ohne Fehler angezeigt, so wird der Sharupd-Modus nach Eingabe des Kommandos SR erst aktiv, nachdem der Benutzer mit dem Kommando "/" in den Kommando-Modus des BS2000 gewechselt und mit /R wieder nach CFS zurückgekehrt ist. | |
| Durch Ausschalten des Single Record-Modus mit dem Kommando NSR wird die Display-Datei wieder mit SHARUPD=NO eröffnet. | |
| Falls der Benutzer jedoch die Display-Datei auch mit SHARUPD=YES im ganzseitigen Modus anschauen und ggf. ändern möchte, so ist das Kommando NSR SHARUPD= YES einzugeben. | |
| Der SR-Modus gilt nur für die aktuelle Display-Datei und muß bei einer neuen Datei gegebenenfalls wieder gesetzt werden. | |
| Editieren sequentieller Dateien/Bibliothekselemente | |
| Die Hilfsdatei kann mit den im letzten Abschnitt beschriebenen ISAM-spezifischen Kommandos bearbeitet werden. | |
| Vor dem Verlassen des CFS-Editors (Kommando LST/Kommando SAM/Drücken der K1-Taste) wird die Hilfsdatei wieder in eine sequentiell organisierte Datei des ursprünglichen Formats zurückkonvertiert, falls der Benutzer auf eine entsprechende Anfrage mit Ja antwortet. Die ISAM-Hilfsdatei wird anschließend gelöscht. Das automatische Löschen der Zwischendatei wird mit dem Kommando SAM,KEEP verhindert. Das genannte Kommando spielt die editierte Zwischendatei ebenfalls in die sequentielle Datei zurück, verhindert aber, daß diese anschließend gelöscht wird. | |
| Display von Banddateien | |
| Nicht katalogisierte Banddateien können ebenfalls mit dem Action-Code Display angezeigt werden. Es ist dazu folgende Vorgehensweise notwendig: | |
| 1) | /FILE datei,LINK=DISP,FCBTYPE=SAM,VOLUME=..., DEVICE=..,STATE=FOREIGN
| |
| 2) | Namen der im File-Kommando angegebenen und damit katalogisierten Banddatei in der Dateienliste selektieren. Am einfachsten geschieht dies durch Eintragen des im FILE-Kommando angegebenen Dateinamens im Feld FILENAME-SELECT. Bei der Datei in der Dateienliste Action-Code D eintragen. | |
| Im Normalmodus des Display wird das Band bei jeder Maskenausgabe, bei dem ein bereits gelesener Satzbereich wieder benötigt wird (z.B. Kommandos H, NH, DS, DW) zurückpositioniert und von Anfang an gelesen. Das Zurückpositionieren des Bandes wird nicht durchgeführt, wenn der SR-Modus (Single Record) eingeschaltet ist. | |
| Mit dem Kommando W (Write) bzw. S...=W (Suchen mit Wegschreiben) wird eine Auswahl von Datensätzen der Banddatei auf einfache Weise in eine Plattendatei übertragen. | |
| Editieren von Banddateien | |
| Auch eine Banddatei mit FCBTYPE=SAM (Recform=V/F/U) kann nach Umsetzung in eine ISAM-Hilfsdatei editiert werden. | |
| Vorgehensweise: | |
| 1) | Falls die Banddatei noch nicht katalogisiert ist, File-Kommando absetzen: | |
/FILE datei,LINK=DISP,FCBTYPE=SAM,VOLUME=..., DEVICE=..,STATE=FOREIGN
| ||
| 2) | Banddatei über die Selektionsmaske selektieren und in der Dateienliste mit Action-Code D markieren. | |
| 3) | Banddatei mit Kommando IS[AM] in ISAM-Hilfsdatei umsetzen. | |
| 4) | Die erzeugte Hilfsdatei wird automatisch im Modify-Modus angezeigt und kann somit mit allen Editieroptionen bearbeitet werden. | |
| 5) | Nach Abschluß des Editiervorgangs ISAM-Hilfsdatei in Banddatei des ursprünglichen Formats umsetzen: Kommando SAM bzw. K1-Taste. | |